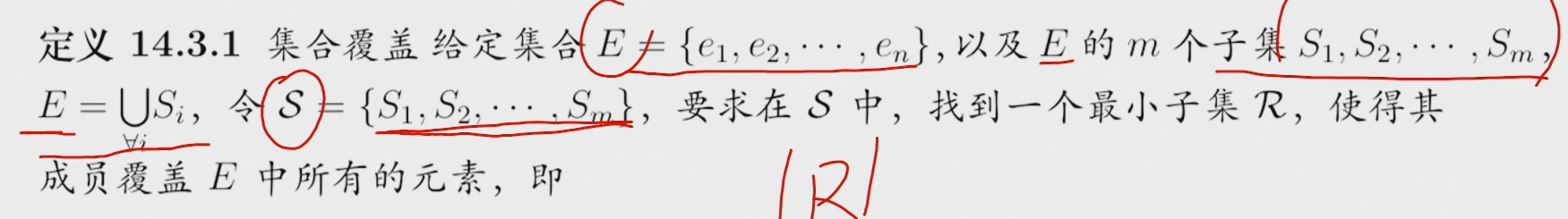线性规划(LP)定义
对满足有限多个线性等式或不等式约束条件的决策变量的一个线性目标函数求最大或者最小值优化问题
- 可行解
- 可行域
- 最优解
- 最优值
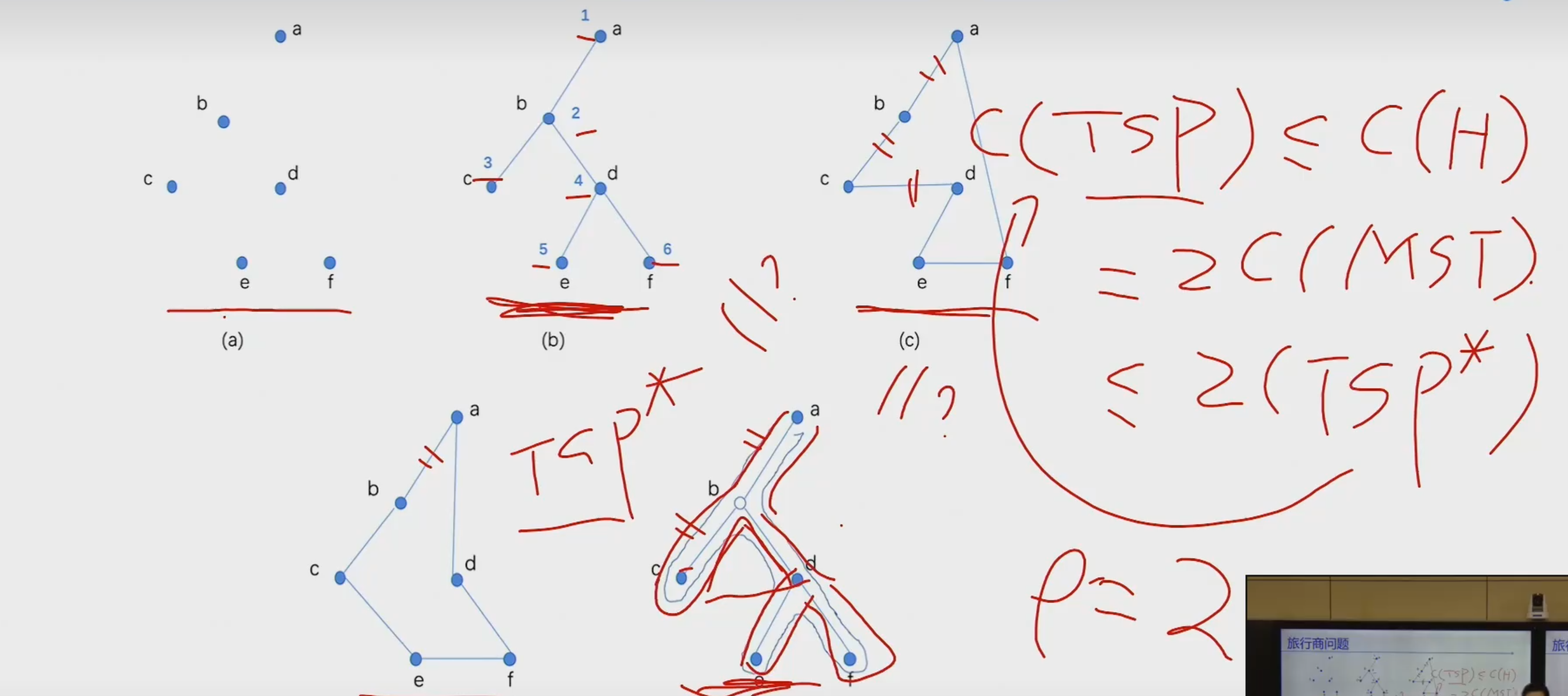
标准型和松弛型

图解法
单纯型法
先化为标准型,然后再变为松弛型,使用单纯型表求解
对偶

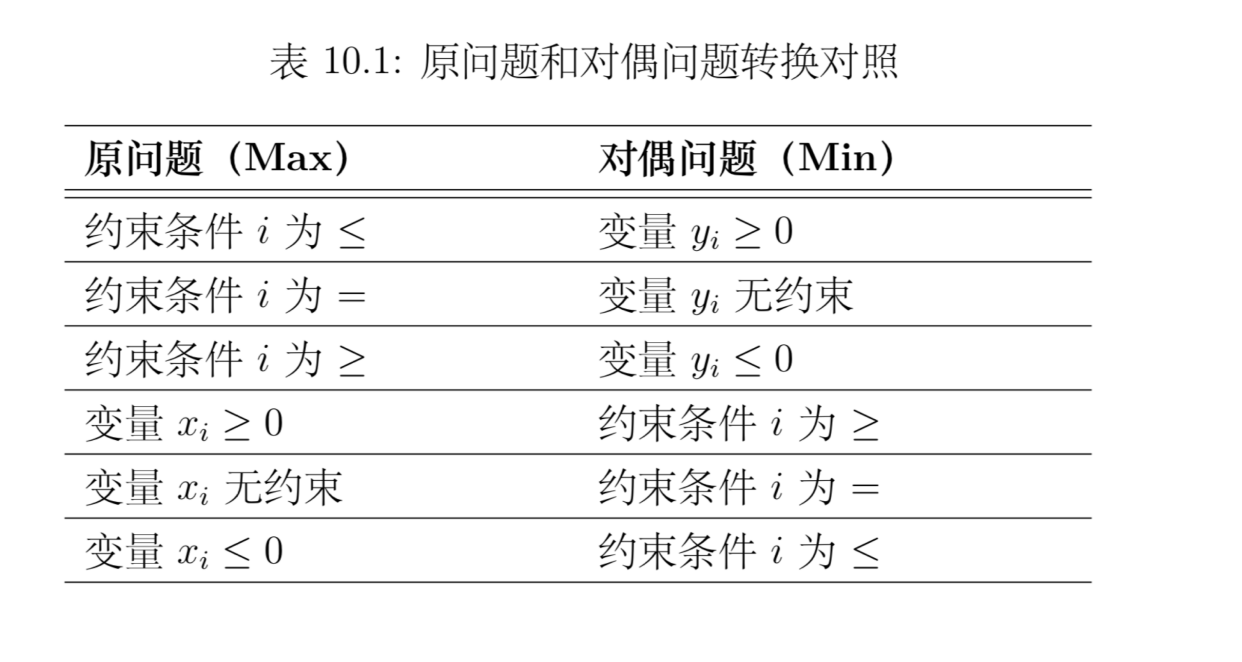
对偶性质


整数规划
先不考虑整数约束条件,然后使用分支限界法确定整数解
0-1 整数规划
隐枚举法
原始对偶算法
通过对偶问题来求解原问题
放宽的互补松弛性


顶点覆盖问题 <-> 图的最大匹配问题

带权重的顶点覆盖问题

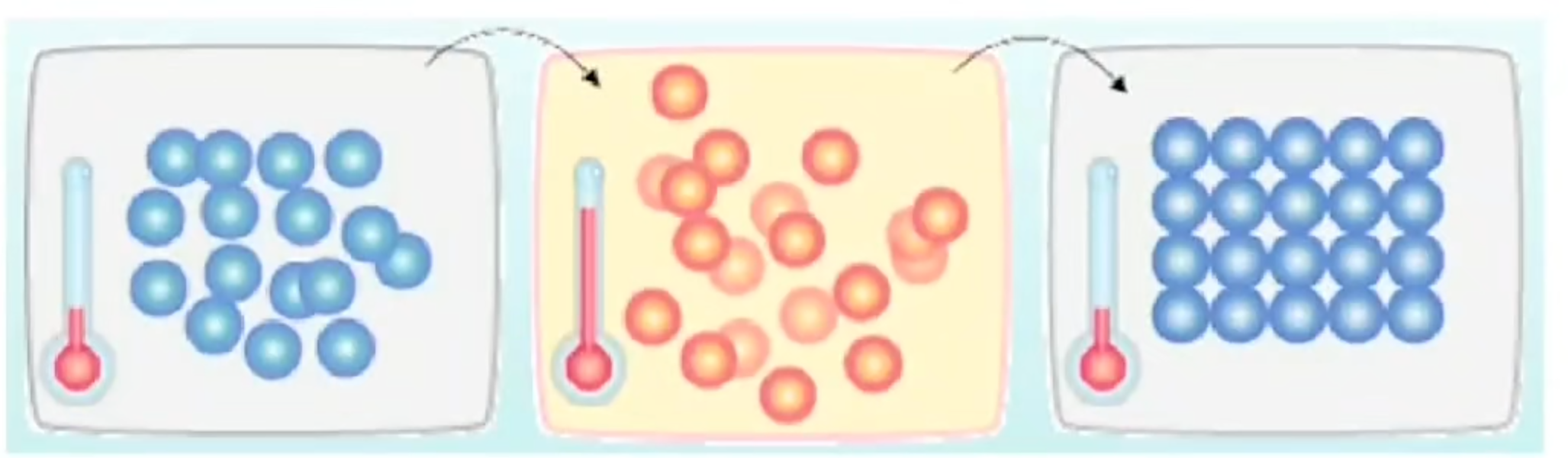
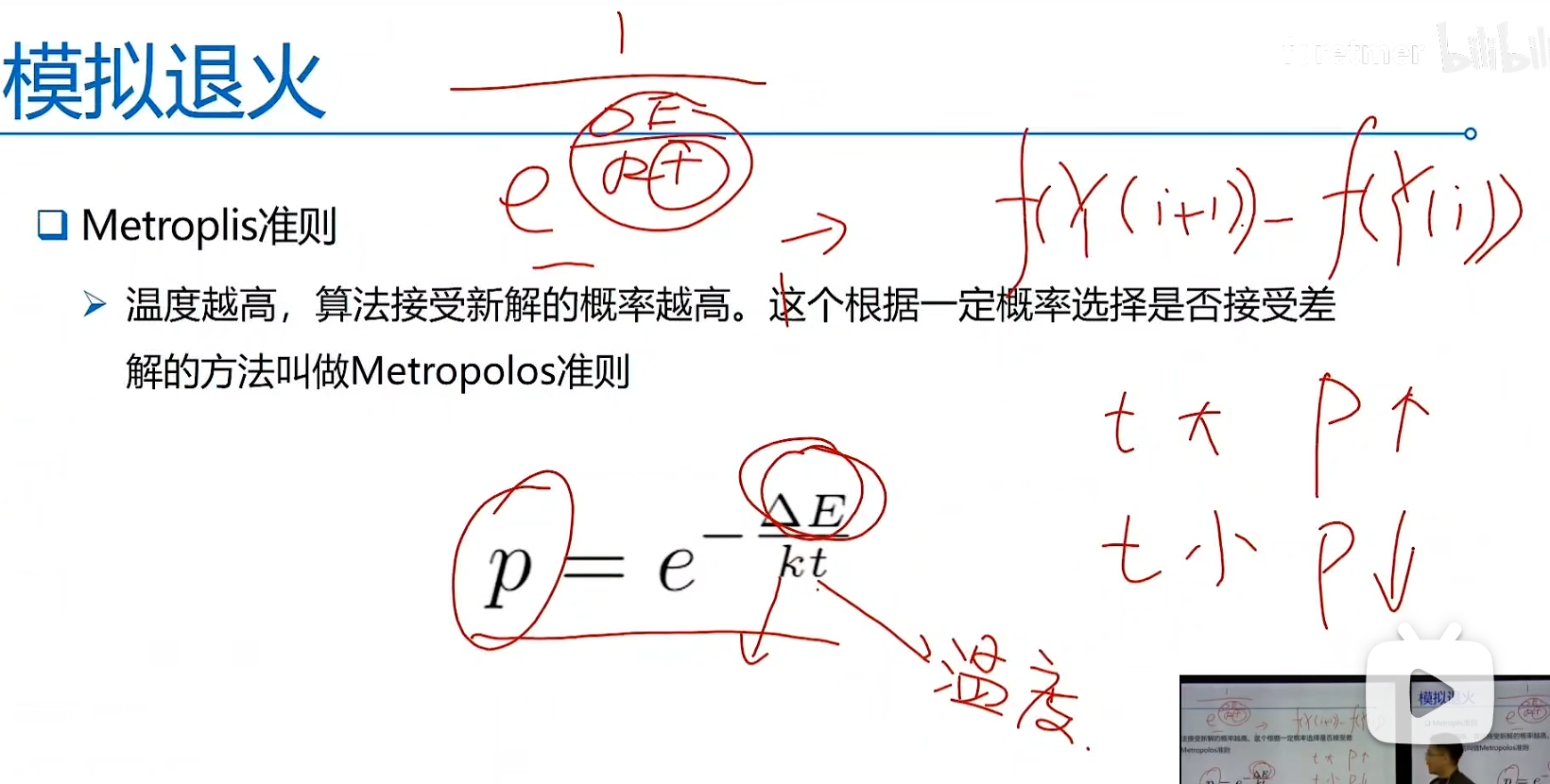
通过对过去经验的归纳推理以及实验分析来解决问题的方法,借助于某种直观判断或试探的方法,以求得问题的次优解或以一定概率求其最优解
从自然界的一些现象取得灵感,通过这些现象获取的额求解过程来解决实际的问题
启发式算法 = 元启发式算法 + 问题特征







当前解进行一个操作(这个操作就是领域动作)可以得到的所有解的集合



候选集合元素选取的一个评价公式


过程见PPT
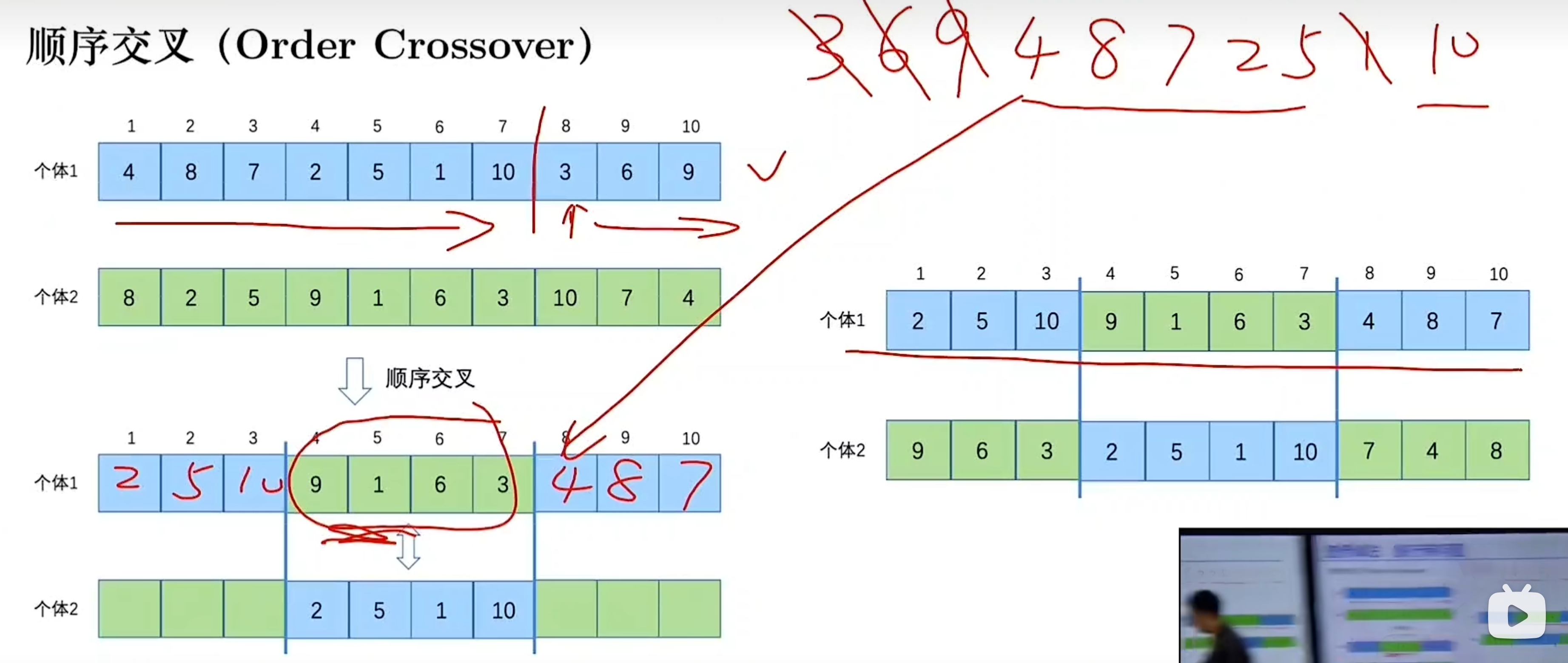
先随机生成一组候选解,候选解中的个体通过交叉和变异产生新的解群,再从中选取较优的个体,重复此过程,直到满足某种收敛指标为止
对应组候选解的集合
对应一个解。在遗传算法中,需要把一个解构造成染色体
染色体由基因构成
按照一定概率将个体中的基因值用其它基因值来替换,从而形成一个新的个体




染色体交叉会出现非法解,通过两种方式解决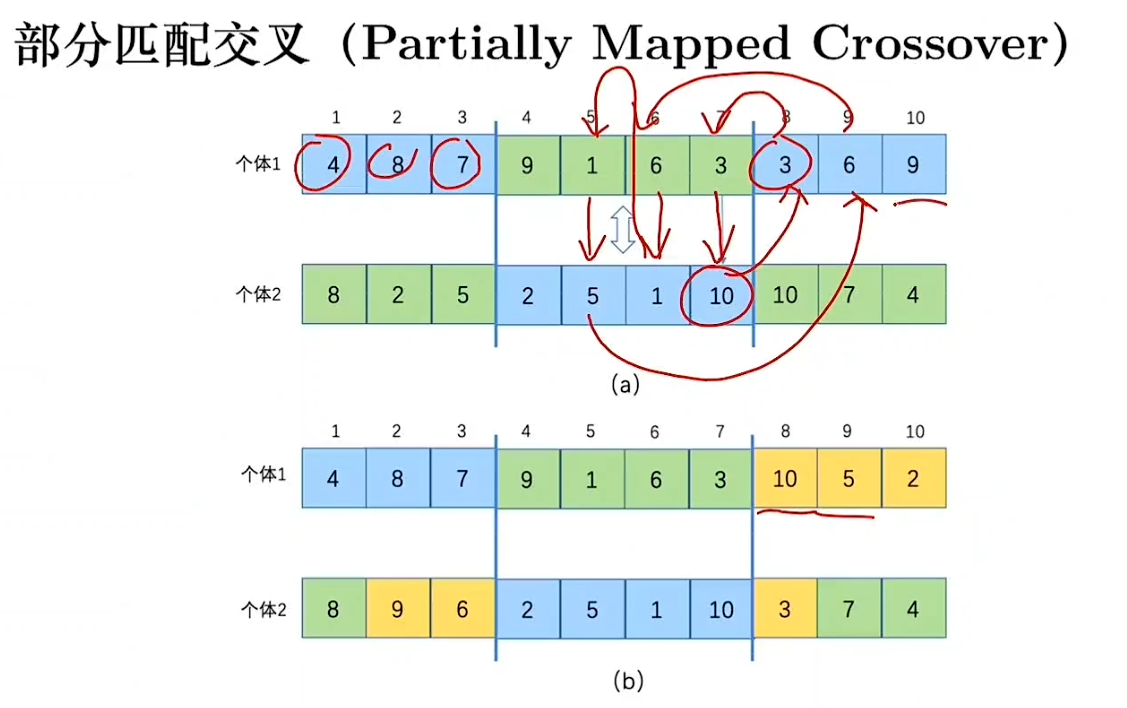
染色体变异也会出现非法解,通过两种方式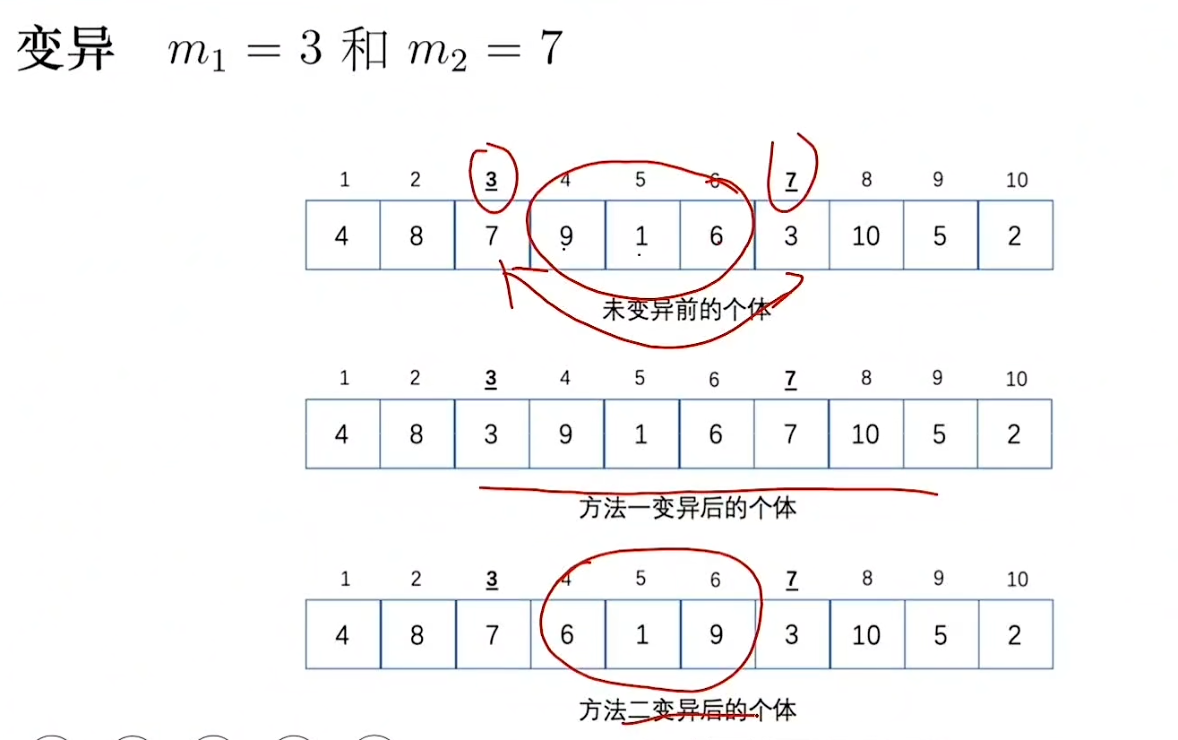






在前面讨论的算法中,问题实例的所有数据在计算时都是已知的
1.问题实例的数据是逐渐来到的
2.在线算法是近似算法
人工智能算法
试图从以往的数据中寻找规律,根据目前分配状态,来分配目前到达的任务
在线算法
数据完全未知,并且存在最坏数据的情况
和近似算法的近似因子十分相似








策略的做出是随机性的,形成随机算法,随机在线算法的好处是,假设对手无法猜测算法的策略


所以对于租买问题,n和c都未知的情况下,在第$c$天购买用具的确定性算法,竞争度最小
其它情况下,最优的确定性算法的策略不一定



姚极小极大原理的证明过程见PPT
待学习……
前面所讲述的算法都是确定性算
当算法引入一些随机因素后,算法将不再具有上述性质
在限定时间内,算法不一定能找到解;如果找到解,一定是正确解
执行时间是确定的,但是解不一定是正确解
这类随机算法也称为舍伍德算法(Sherwood)





基于随机增量法的最小圆覆盖的最差时间复杂度为$O(n^3)$,期望时间复杂度为$O(n)$


弗里瓦德算法得到错误解的概率小于等于$1/2$


随机算法通过收缩的方式来找最小割






1.多项式时间复杂度(O(n)、O(nlogn)、O($n^2$)、O($n^{10}$))
2.非多项式时间复杂度(O($n^{logn}$)、O($2^n$)、O($n!$))
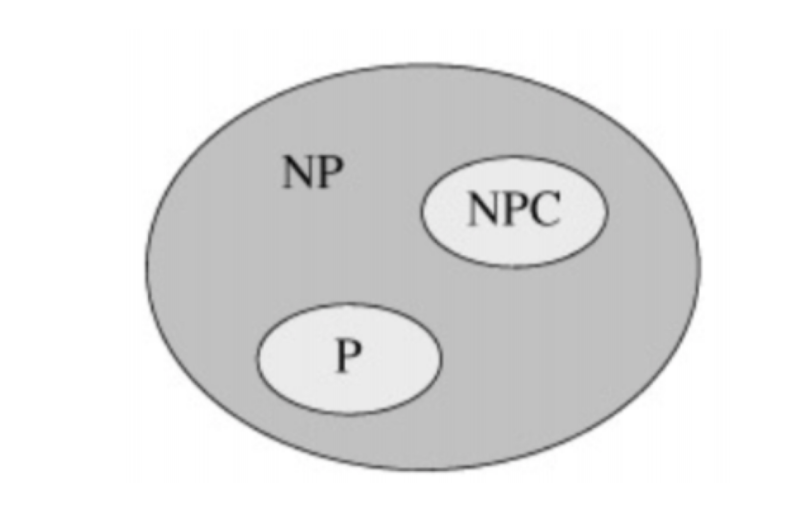
多项式时间内可以解决的问题
就是对于一个给定的解,能够在多项式时间内验证其是否正确的问题
所有的P问题都是NP问题
需满足两个条件
1.是一个NP问题
2.所有NP问题都可以归约成此问题


是否存在一个赋值使得2CNF为真
给定一个逻辑电路,是否存在一种输入使得输出为True
1.它是一个NP问题,可以在多项式时间判断解是否正确
2.电路可满足问题可以 规约 到公式可满足问题
1.它是一个NP问题,可以在多项式时间判断解是否正确
2.公式可满足问题可以 规约 到3CNF-SAT问题
团问题是关于寻找图中规模最大的团的最优化问题
我们仅仅要考虑的是:在图中是否存在一个给定规模为k的团
1.它是一个NP问题,可以在多项式时间判断解是否正确
给定义一个图G的顶点集,可以在多项式时间判断它是否是团
2.3CNF-SAT问题可以 规约 到团问题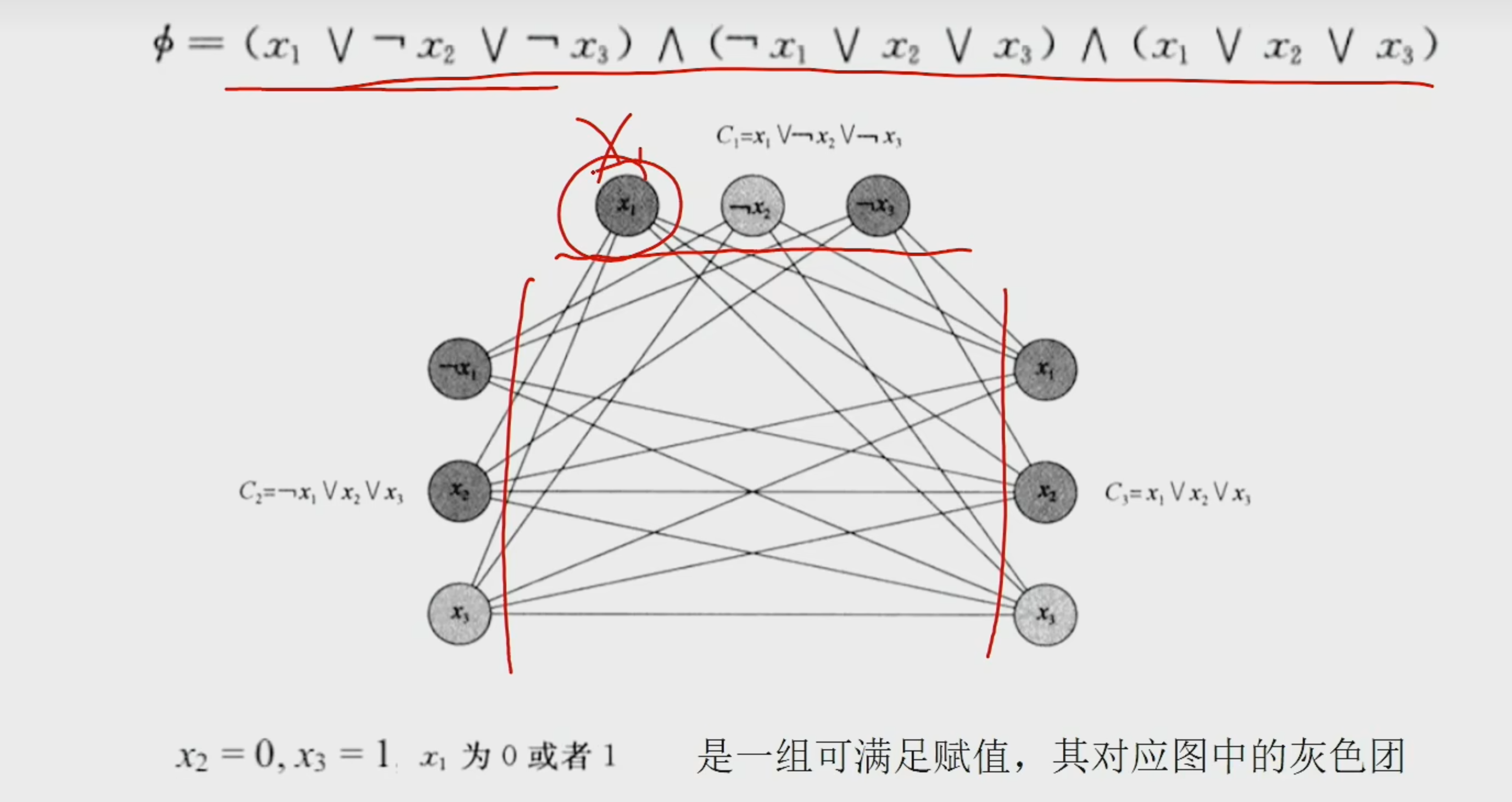
输出一致性:
若3CNF-SAT有真,则必然所有子句都为真,则子句内有真,真值之间都是互联的,所以有团
找出最小数目的顶点集合S,使得G中的每条边都至少被集合S中的一个顶点覆盖
1.它是一个NP问题,可以在多项式时间判断解是否正确
2.团问题可以 规约 为顶点覆盖问题
原图和补图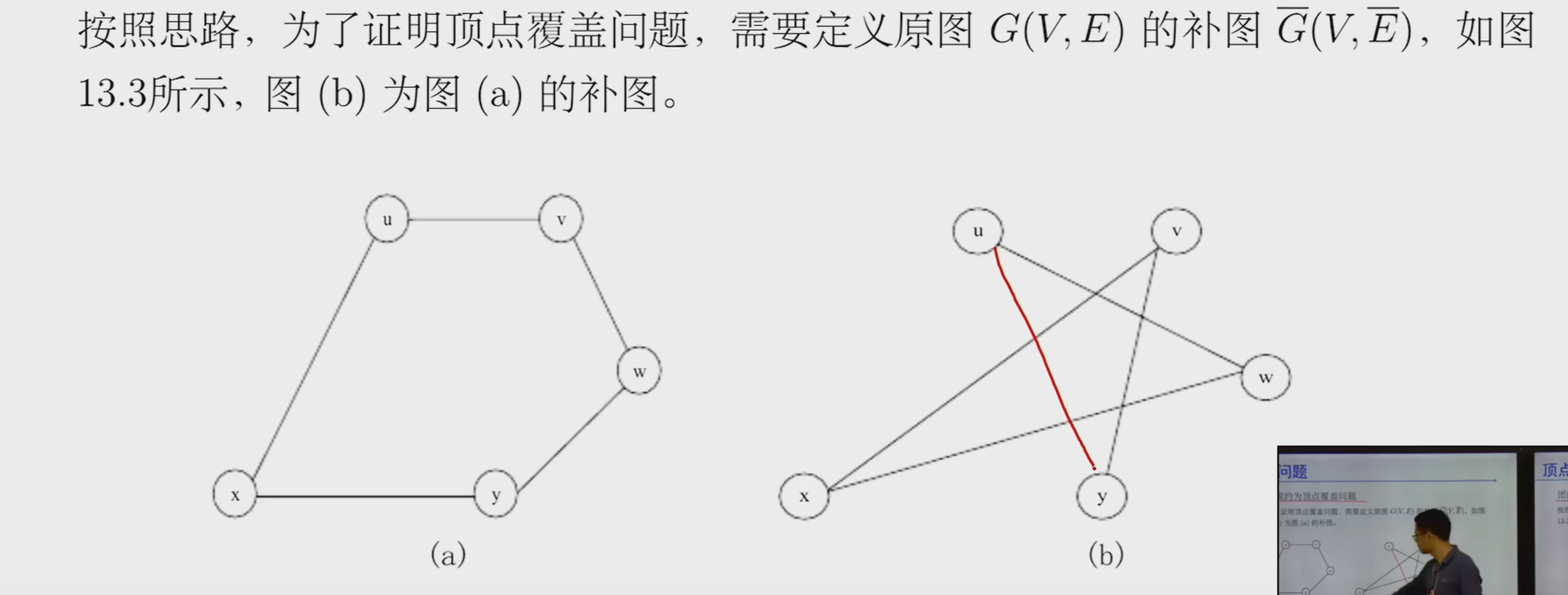



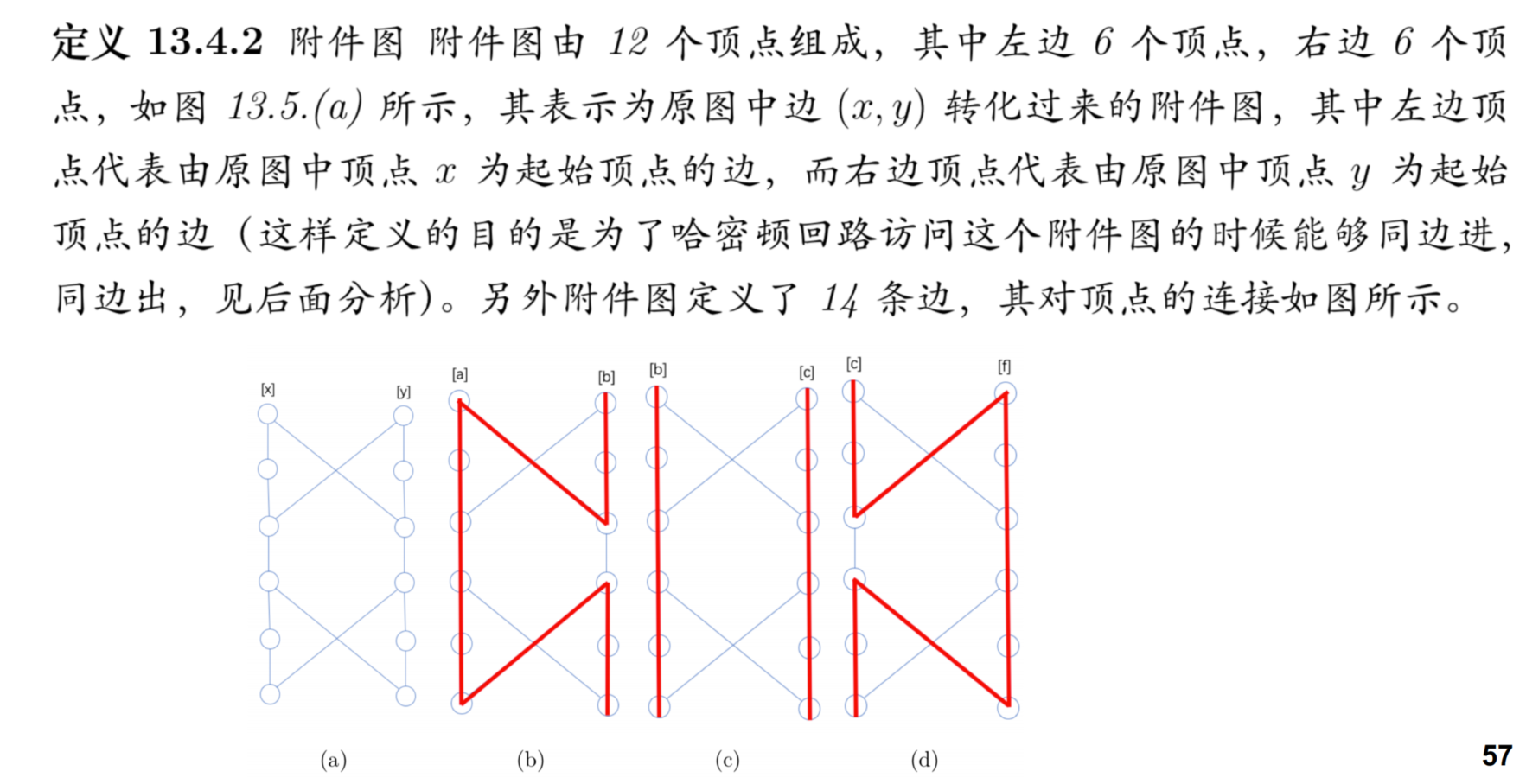
在一个图(通常指无向图)中,从某个顶点出发,经过其它顶点一次且仅一次的回路称作哈密顿回路。将这个问题转为一个判断性问题“给定一个图,判断它是否包含哈密顿回路”
1.它是一个NP问题,可以在多项式时间判断解是否正确
2.顶点覆盖问题可以 规约 为哈密顿回路问题
转化后的图中有顶点数:12m + k
转化后的图中有边数:14m + 2m - n + 2kn
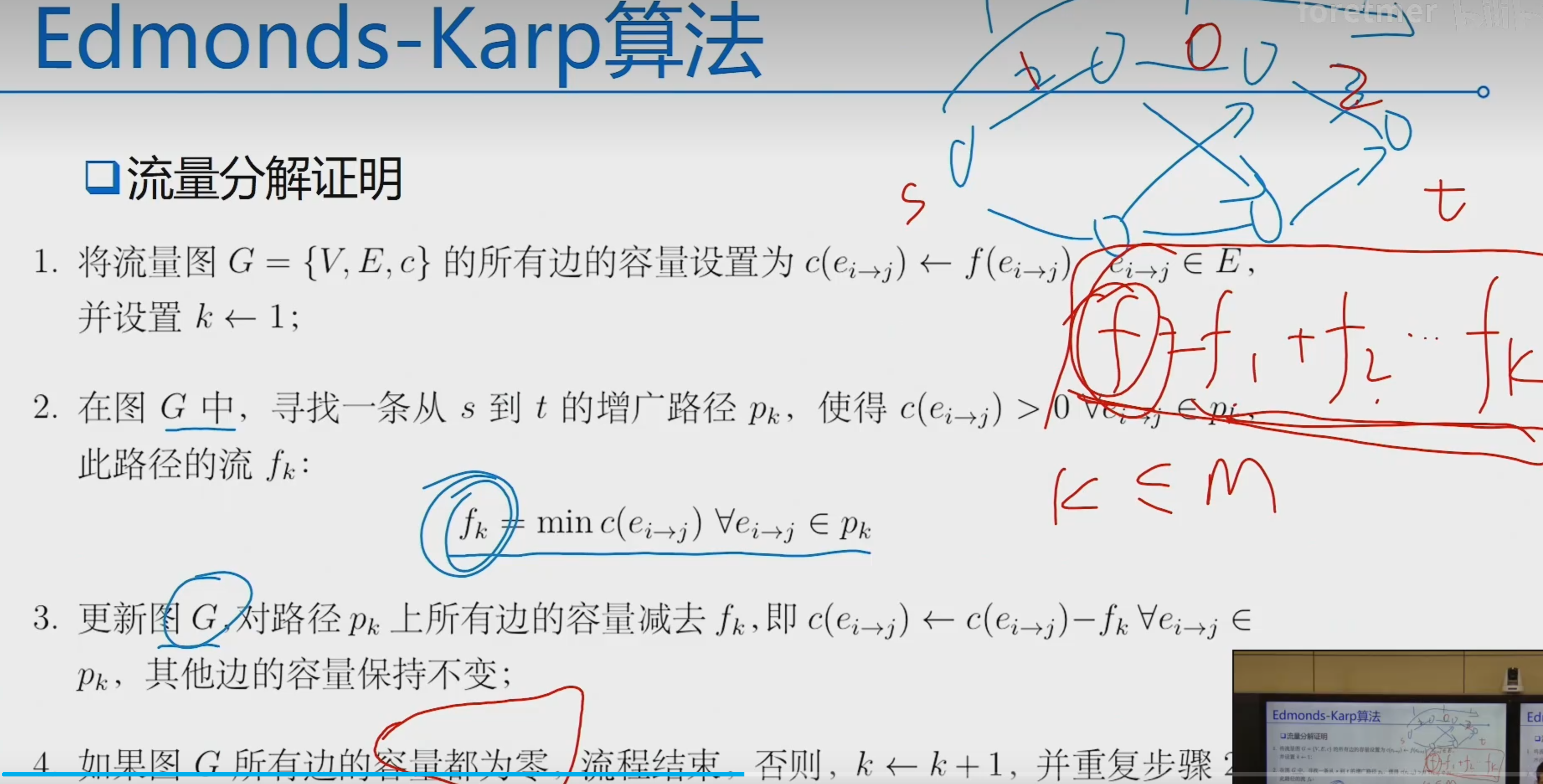
找到一个从s出发,到t的流量最大的流
1.从流量为0开始,逐步增加流量
2.从s出发,找到一条道t的可行路径,并将流增加到这个路径能够支持的最大路径
3.在残存网络再找一条可行路径,增加相应的流
4.重复以上步骤
将所有点划分为两个集合,这两个集合连接的边的集合称为割或者切
图是带权重的,划分的所有集合中,权重和最小的割
划分的两个点的集合,必须是一个包含s,一个包含t
下面三个是等价的:
1.f是G的最大流
2.残存网络$G_f$找不到任何从s到t的新路径
3.s-t最小割和最大流是相等的



Dijkstra的改造




特征向量中心性算法的一个变体


对网络进行社群划分的算法
衡量社群划分好坏的一个指标,模块度的值越大,表示划分的越好
1.合并方式
2.分割方式
LouVain算法待研究……


团的定义:图的一个子图,其中任意顶点之间都有边连接,即团是一个完全子图
极大团的定义:如果一个团不包含在任何更大的团中,那么这个团称为极大团
最大团的定义: 顶点数最多的极大团

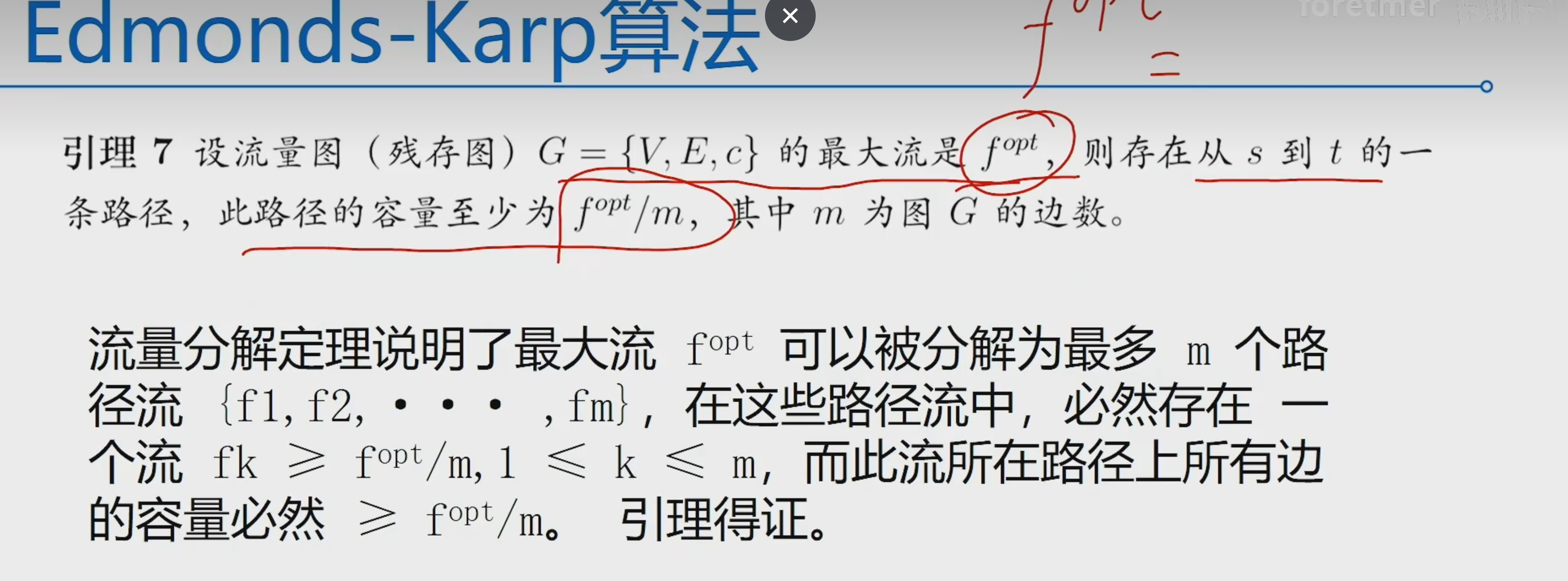
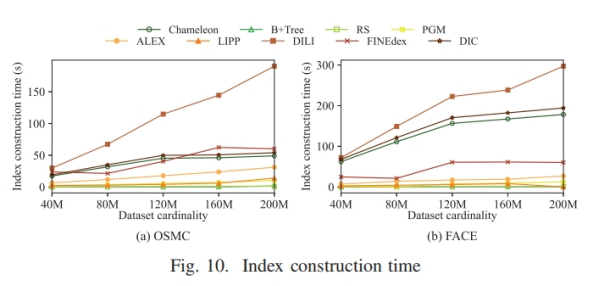
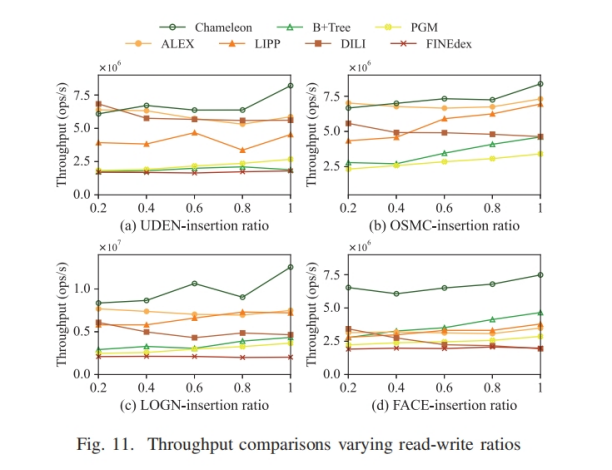
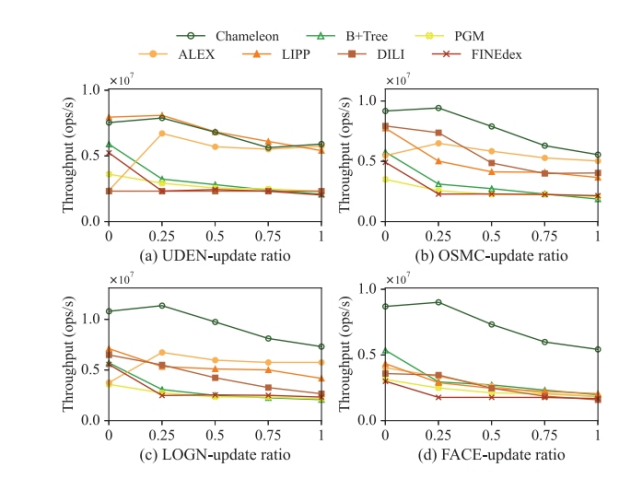
关键词:learned index,locally skewed data,multi-agent reinfocement learning
(1)学习索引利用机器学习模型去拟合局部区域内的数据分布具有挑战性
现存的工作(比如ALEX,PGM, FITing-tree采用贪心构建策略来拟合整体数据分布)无法很好地适应局部数据的偏斜分布
(2)频繁插入数据而进行的重新构建或者重训练对查询延迟有显著影响
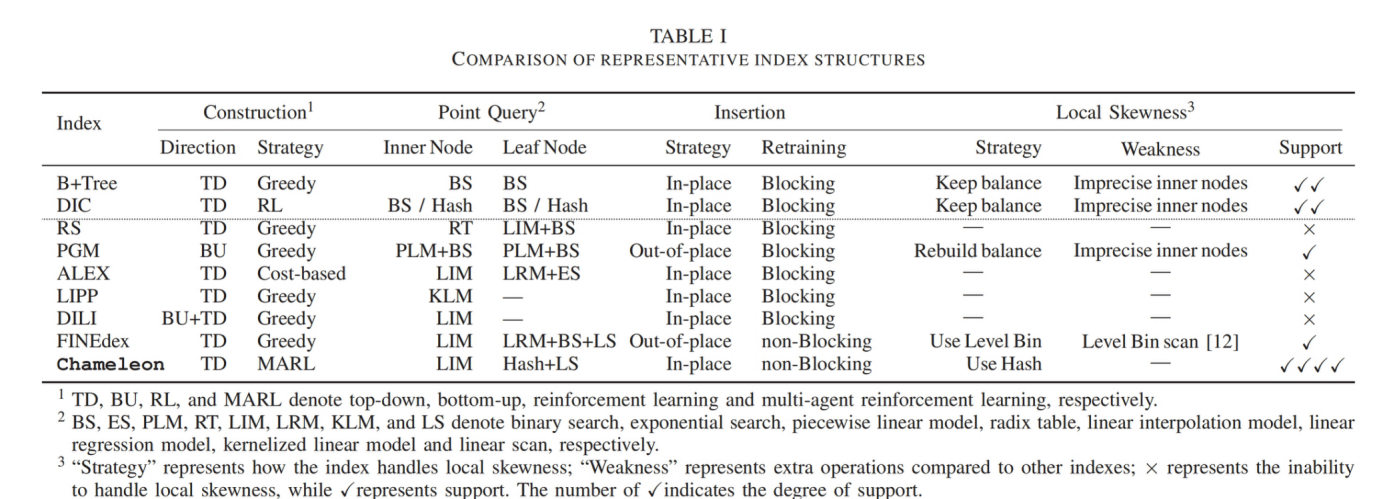
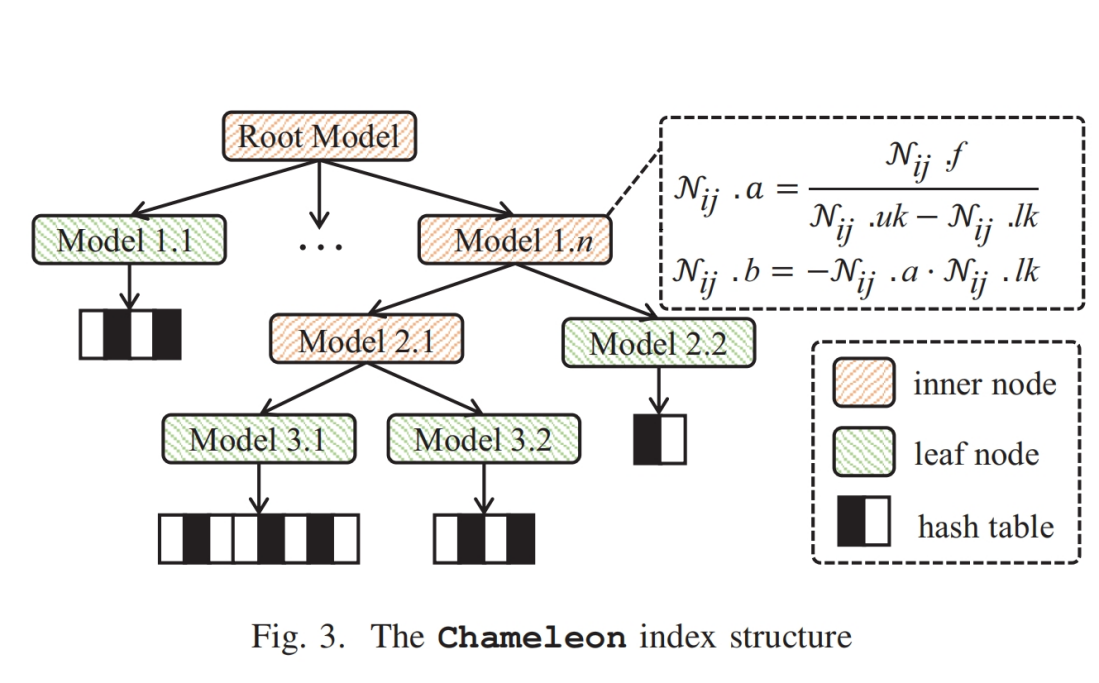
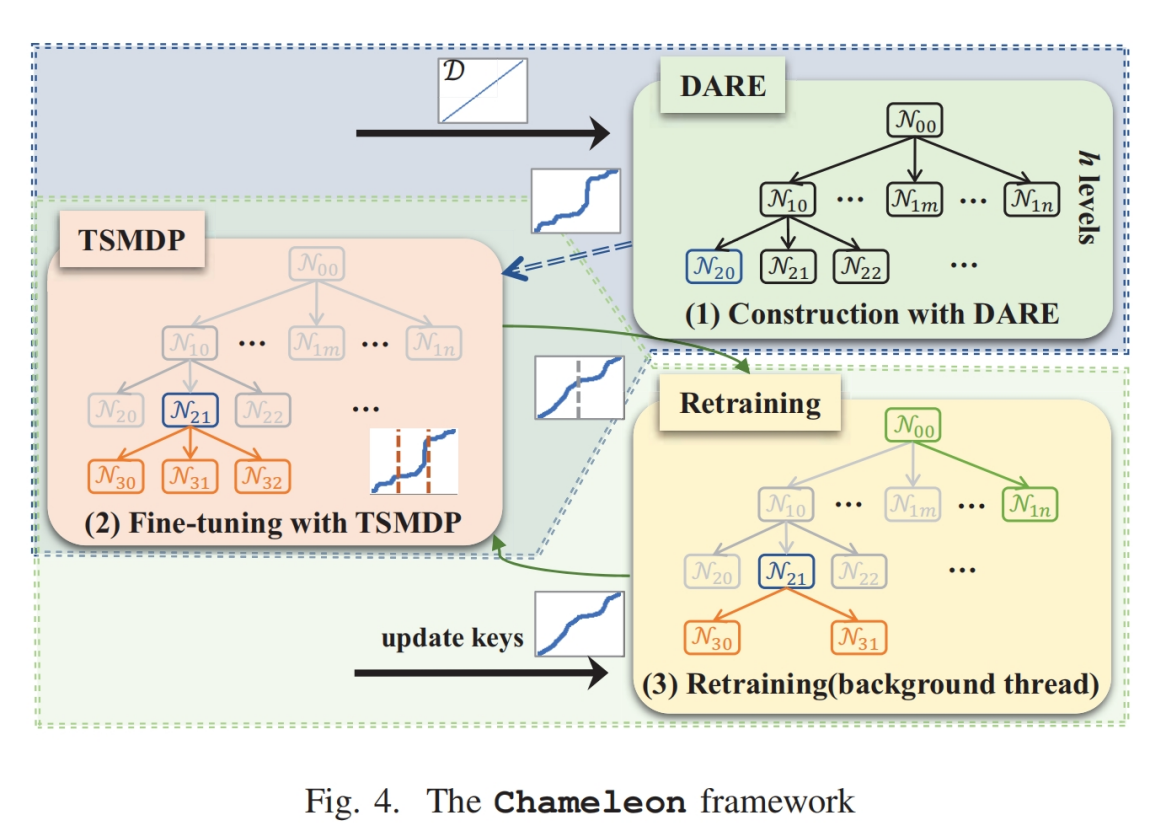
(1)提出了一个名为Chameleon的一维学习型索引,分为non-leaf node(使用linear model)和leaf node(使用EBH(Error Bounded Hashing) model)
(2)提出了一个测量local skewness的指标,提出MARL(Multi Agent Reinforcement Learning)方法用来构建索引结构和定位局部倾斜的区域
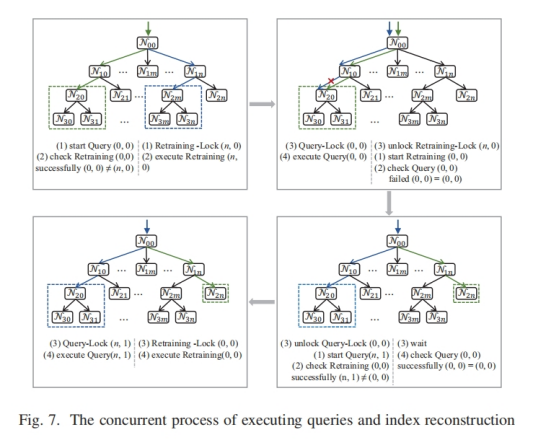
(3)提出一个轻量级锁(名为interval lock)和一个基于此的无锁重训练机制,
(1)、(2)解决了问题1,(3)解决了问题2

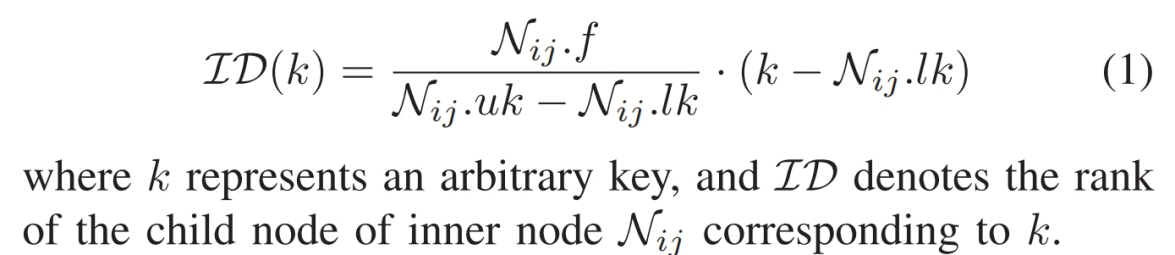
因为输入的微小变化可以导致相应的哈希值的显著变化,使得哈希函数能够分散密集数据,从而有效降低索引树的高度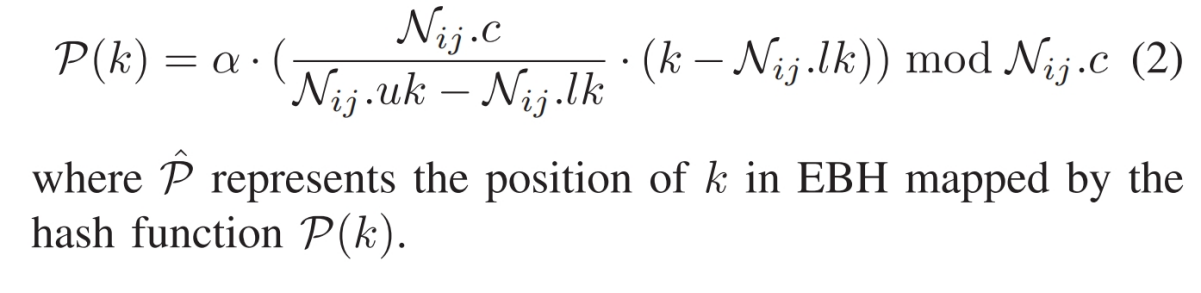
解决局部倾斜问题的关键在于如何测量和识别这种偏斜,以及在数据更新时可能导致局部偏斜区域的变化

提出MARL(Multi Agent Reinforcement Learning)方法用来构建索引结构和定位局部倾斜的区域
为了有效解决局部偏斜问题,我们根据定理1自适应地调整每个叶子节点 $ N_{ij}.c $ 的容量,以确保每个节点满足所需的 $ \tau $ 值。
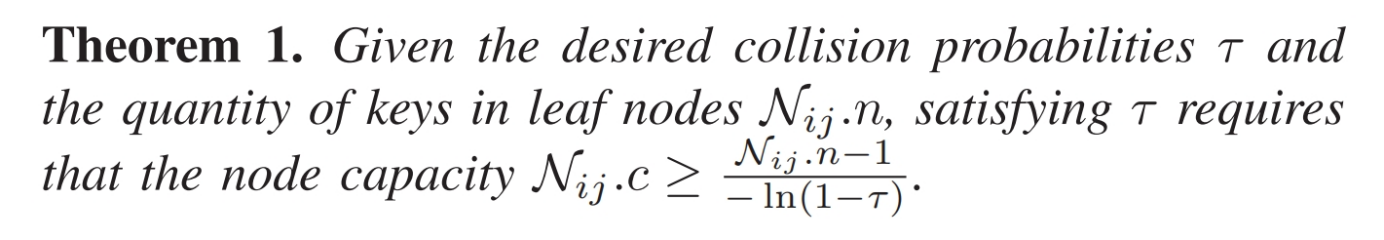
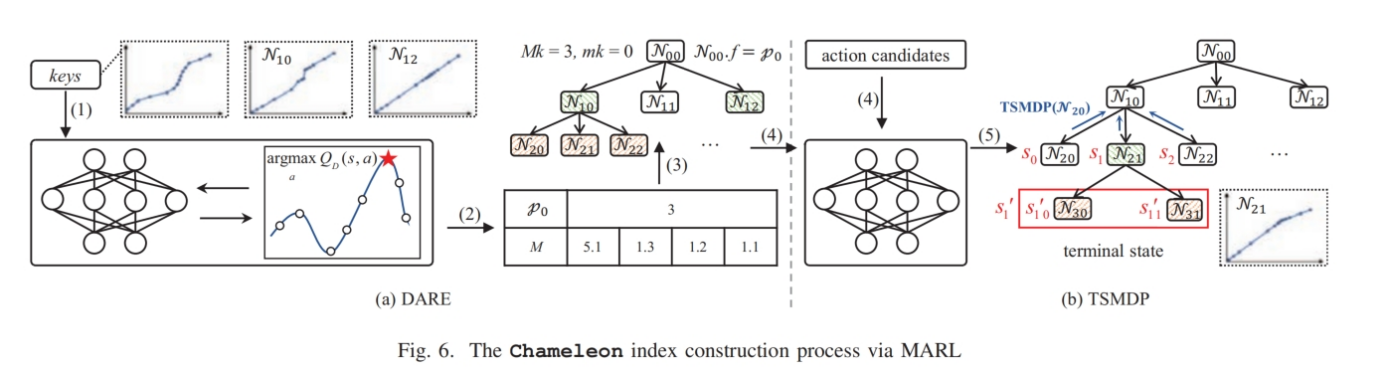
在索引构建过程中,每个内部节点都会影响其所有子节点。现有的基于马尔可夫决策过程(MDP)的强化学习算法侧重于顺序决策问题,无法直接应用于我们的基于树的决策过程。为了解决这一问题,我们提出了一个树结构马尔可夫决策过程(TSMDP),基于深度 Q 网络(DQN)的思想。以与节点 $ N_{ij} $ 对应的数据集特征作为输入,TSMDP 输出节点 $ N_{ij} $ 的扇出 $ N_{ij}.f $。接下来,我们定义 TSMDP 过程,并介绍训练过程。
State:状态s是节点划分之前的信息,包括PDF,key的数量,lsn(其中PDF由大小为bt的桶表示)
Action:动作a是指分配给当前状态对应节点的fanout,动作空间是一个离散值的预定义值
Transition:给定s和a,如果a = 1,则TSMDP到达一个终止状态,并构建一个叶子节点。由于基于树的索引结构的特点,当前状态s可能会导致多个下一个状态{s1,s2}
Reward function:评估在给定s和a下构建的索引的查询成本和内存成本
$ r = -w_t \cdot R_t - w_m \cdot R_m $。其中,$ w_t $ 和 $ w_m $ 表示查询时间奖励和内存奖励的权重系数。我们用 $ R_t $ 表示遍历树和在叶节点内进行二次搜索的成本,用 $ R_m $ 表示执行动作后节点的内存使用量。根据应用需求,还可以将查询分布等其他因素加入到奖励函数中
学习算法:带经验回放(experience replay)的DQN
智能体的经验,包括状态、动作、奖励和下一状态 $(s_t, a_t, r_t, s_{t+1})$ ,在每个时间步 $ t $ 进行存储。在每一步中,使用Boltzmann 探索策略来选择动作。我们实现了两个网络:一个为参数为 $ \theta $ 的策略网络 $ Q_T $ ,另一个为参数为 $ \theta^{-} $ 的目标网络 $ \hat{Q}_T $ ,这种设置使 TSMDP 比使用单一网络更稳定。
给定一批转换 $(s, a, r, s’)$ 后,通过最小化平均绝对误差(Mean Absolute Error,MAE)损失来使用梯度下降更新策略网络的参数 $ \theta $ 。具体而言,损失函数为: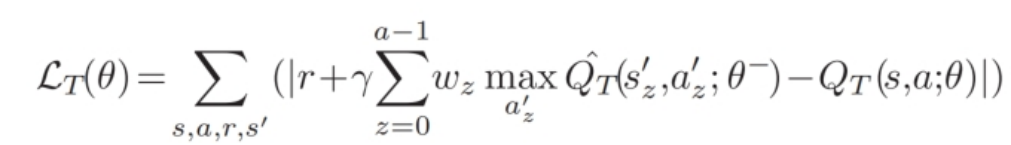
其中,$ \gamma \in (0, 1) $ 表示折扣因子,决定了未来奖励的重要性,$ a’_z $ 表示由 $ s’_z $ 所采取的最优动作。$ w_z $ 是 $ s’_z $ 的权重,即 $ s’_z $ 中键数量与 $ s $ 中键数量的比值。
请注意,目标网络的参数 $ \theta^- $ 仅在每隔 $ K $ 个步骤(系统参数)时与策略网络的参数 $ \theta $ 同步,而在其他时间保持不变。
1.索引构建时间很长,因为需要递归调用TSMDP模型为每个节点做出决策
2.高训练开销。在训练过程中,每个经验都包含了每个节点及其所有子节点的概率密度函数 (PDF)。逐一使用 $ Qˆ_T $ 计算子节点的 $ Qˆ_T(s’, a’) $ 的过程非常耗时。同时,离散动作空间的使用限制了我们在更大动作空间中的探索能力。
3.当应用需求发生变化时(例如,奖励函数优先考虑查询时间而非索引大小,或反之),TSMDP需要重新训练
为了解决限制 (1),Chameleon 只需调用 DARE 一次来构建索引的上层 $ h $ 层,仅对下层进行局部 TSMDP 调用以进行微调。
为了解决限制(2),DARE 使用单步决策的强化学习模型,该模型具有较低的训练开销,使我们可以在一个大且连续的动作空间中探索,以找到最佳动作。
为了解决限制 (3),我们提出了一个动态奖励函数,使其能够适应系统动态约束,而无需重新训练强化学习代理。
具体来说,给定一个数据集 $ D $,其最大和最小键分别为 $ M_k $ 和 $ m_k $,DARE 首先提取全局数据分布特征。基于这些特征,它输出一个固定大小的参数矩阵 $ M(h - 2, L) $ 和根节点的分支因子 $ p_0 $(根节点的分支因子作为一个单独的输出参数,因为它在索引中具有唯一性)。这里,$ h $ 表示层数,矩阵 $ M $ 的每一行代表第 $ i $ 层中各个非根内节点的参数 $ p_{i,0}, p_{i,1}, …, p_{i,L-1} $
在获得 $ M $ 和 $ p_0 $ 后,我们首先计算节点 $ N_{ij} $ 在 $ M $ 中的位置 $ x $ 的映射,其中 $ x = \frac{\frac{(N_{ij}.lk + N_{ij}.uk)}{2} - m_k}{M_k - m_k}{(L-1)} $。接下来,计算矩阵 $ M $ 中包含 $ x $ 的区间 $[p_{i,l}, p_{i,l+1}]$,其中 $ l = \lfloor x \rfloor $。然后,我们采用分段线性插值函数将离散参数转换为连续值,公式为:
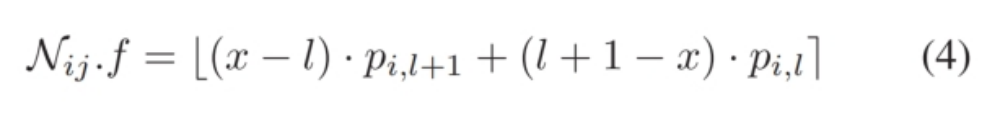
在构建了上层 $ h $ 级索引后,基于 DARE 构建的索引,TSMDP 精细化下层,决定是否继续分裂。在这里,索引构建完成。
如图 6 所示,假设 $ h = 3 $,$ L = 4 $,最小键 $ m_k = 0 $ 和最大键 $ M_k = 3 $。在步骤 (1) 中,提取数据集特征并作为 DARE 的状态。在步骤 (2) 中,DARE 输出根节点的分支因子 $ p_0 $ 和一个 $ 1 \times 4 $ 的参数矩阵 $ M $。由于 $ p_0 = 3 $,根节点有三个子节点,其中 $ N_{10}.lk = 0 $ 和 $ N_{10}.uk = 1 $。因此,计算 $ x = \frac{\frac{(0+1)}{2} - 0}{3-0}\cdot 3 = 0.5 $,并得到 $ l = \lfloor x \rfloor = 0 $。最后,得到 $ N_{10}.f = (0.5 - 0) \cdot 1.3 + (1 - 0.5) \cdot 5.1 = 3.2 \approx 3 $。
Experience: 由于DARE处理的是单步强化学习问题,经验仅包含state,action,reward
State: 我们还使用概率密度函数(PDF,表示为大小为 bD 的向量)、|D| 和局部偏斜度(lsn)来表示状态 sD。因此,状态空间的大小为 bD + 2。
Reward:为了适应不断变化的应用需求,我们提出了一种动态奖励函数(Dynamic Reward Function,DRF),表示为 $ r_D $ = $\sum_{i=1}^{n} w_i \cdot \text{cost}_i $。
假设一个深度Q网络(DQN)已经训练好,可以将高维状态空间和动作空间映射到低维成本空间。给定系数权重 $ w_i $(根据一些特定要求,使得 $ \sum_{i=1}^{n} w_i = 1 $)和不同应用特定指标的成本 $ \text{cost}_1, \text{cost}_2, \ldots, \text{cost}_n $,DRF 可以预测奖励 $ r_D $。当这些权重发生变化时,Q函数仍然有效。
action: 动作$ a_D $ 代表一组参数,用于确定上层 $ h - 1 $ 级节点的扇出(fanout)。根节点的更大扇出有助于提高学习索引的查询性能。大多数现有的一维学习索引的根节点扇出设置在 20 到 220 之间,例如 ALEX。因此,根节点的扇出在范围 [20, 220] 内进行搜索。对于内节点,根据现有的研究,扇出范围设置为 [20, 210],。对于 DARE 的 $ (h - 2) \cdot L $ 参数矩阵,每行向量的大小 $ L $ 设置为 256。
为了提供稳定的动作选择策略,DARE 利用遗传算法(Genetic Algorithm,GA)作为行为者,并使用深度Q网络(DQN)作为评论者。在这种方法中,GA 将动作视为基因,将 $ Q_D(s_D, a_D) $ 作为给定状态的适应度函数。通过数值变异和交叉的方式迭代提高适应度,GA 逐渐识别出最接近最大值的动作,从而确定最优策略。算法 1 概述了使用 GA 输出最优参数的过程。

算法 2 总结了整个 Chameleon 的训练过程。
首先,我们初始化
TSMDP 策略网络 $ Q_T $、
目标网络 $ \hat{Q}_T $、
DARE 策略网络 $ Q_D $、
探索概率 $ e_r $ 和探索终止概率(第 1-2 行)。
$ e_r $ 决定在选择 $ a_D $ 时探索与利用之间的倾向。我们使用大量真实和合成数据集作为训练集。随后,在每个回合中,我们从训练集中随机选择一个数据集 $ D $ 并提取其特征作为 $ s_D $(第 3-6 行)。我们随机生成 DRF 的权重 $ w $(第 7 行),并根据算法 1 获取 $ s_D $ 和 $ w $ 的最佳参数 $ a_{\text{best}} $(第 8 行)。参数 $ a_{\text{random}} $ 是随机生成的(第 9 行)。为了在探索和利用之间取得平衡,DARE 根据 $ e_r $ 选择一组参数 $ a_D $(第 10 行),其中 $ e_r $ 在训练过程中逐渐从 1 降至 0。通过 $ a_D $ 和 $ Q_T $ 实例化 Chameleon-Index(第 11-12 行)。然后,我们训练 TSMDP $ Q_T $ 和 DARE $ Q_D $(第 13-14 行)。最后,我们减少 $ e_r $ 并重复上述过程,直到达到 $ \epsilon $(第 15 行)。损失函数为:
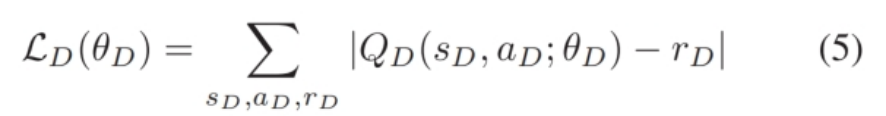
其中 $ \theta_D $ 代表 $ Q_D $ 的参数。

使用后台线程重训练索引,不阻塞查询过程

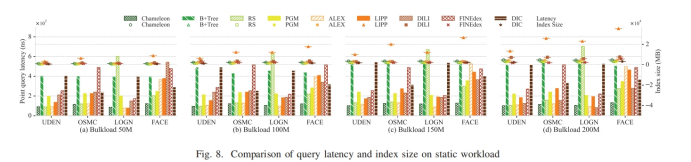
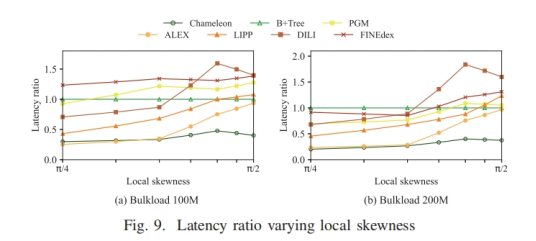
时间复杂度分析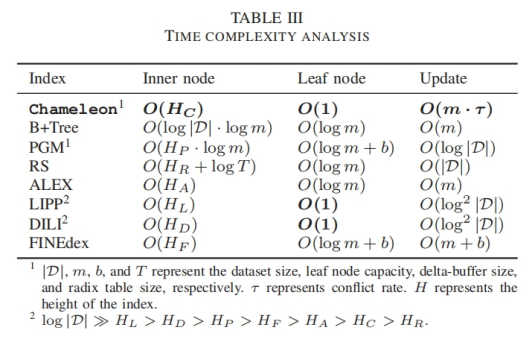




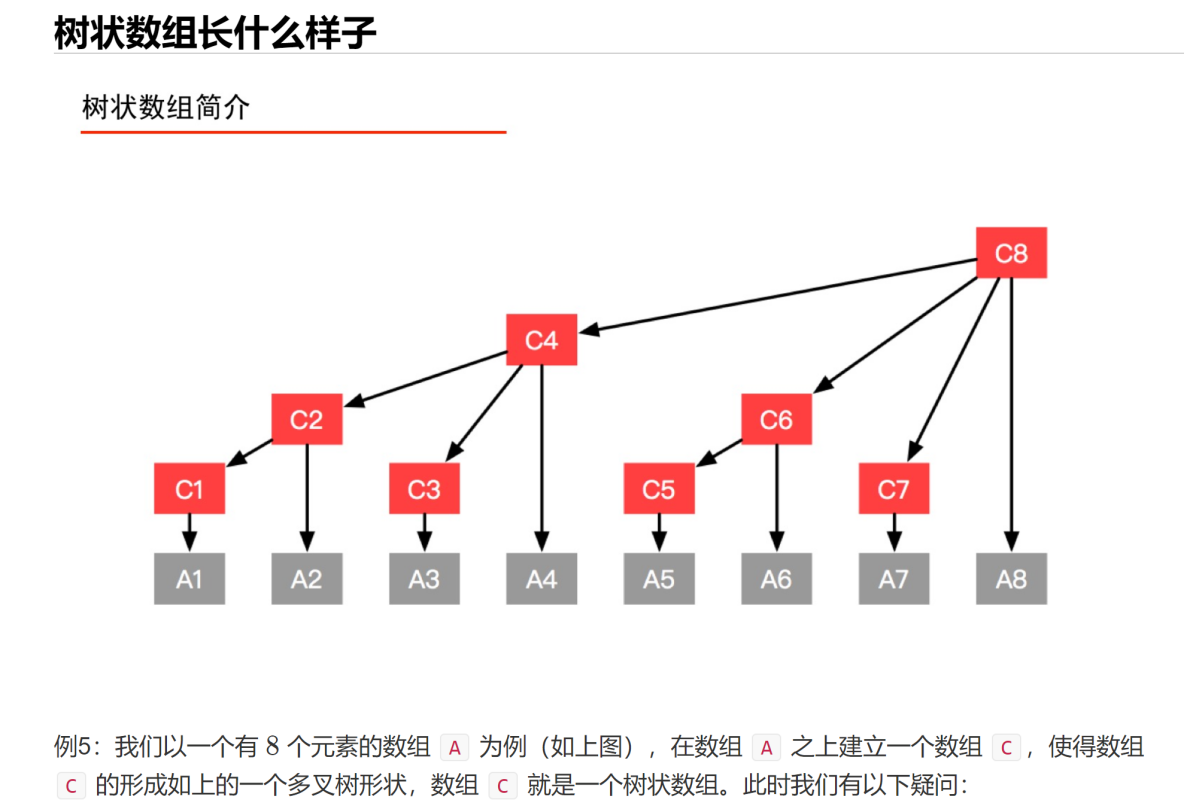
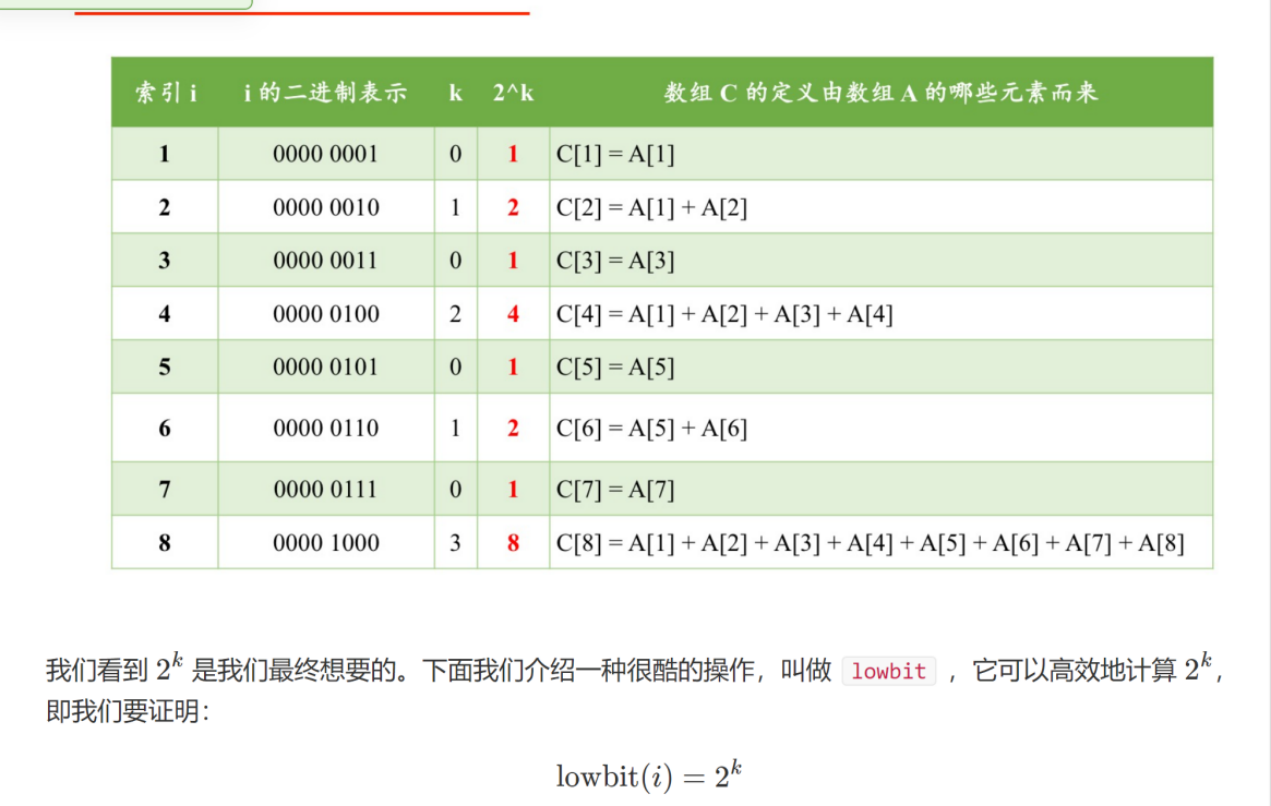
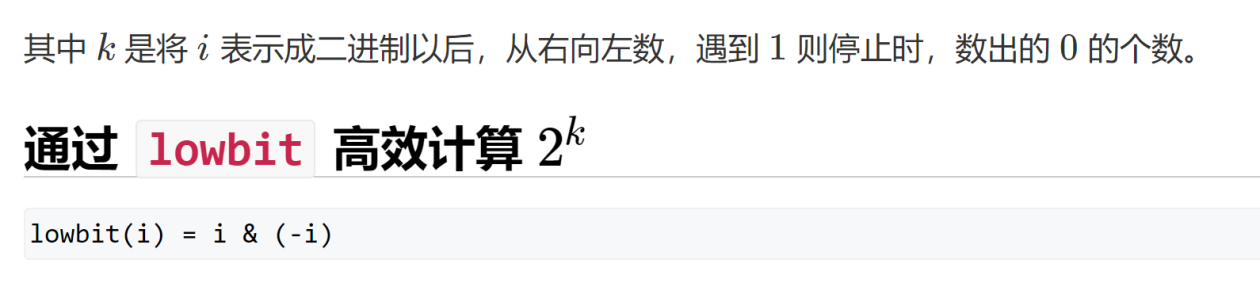
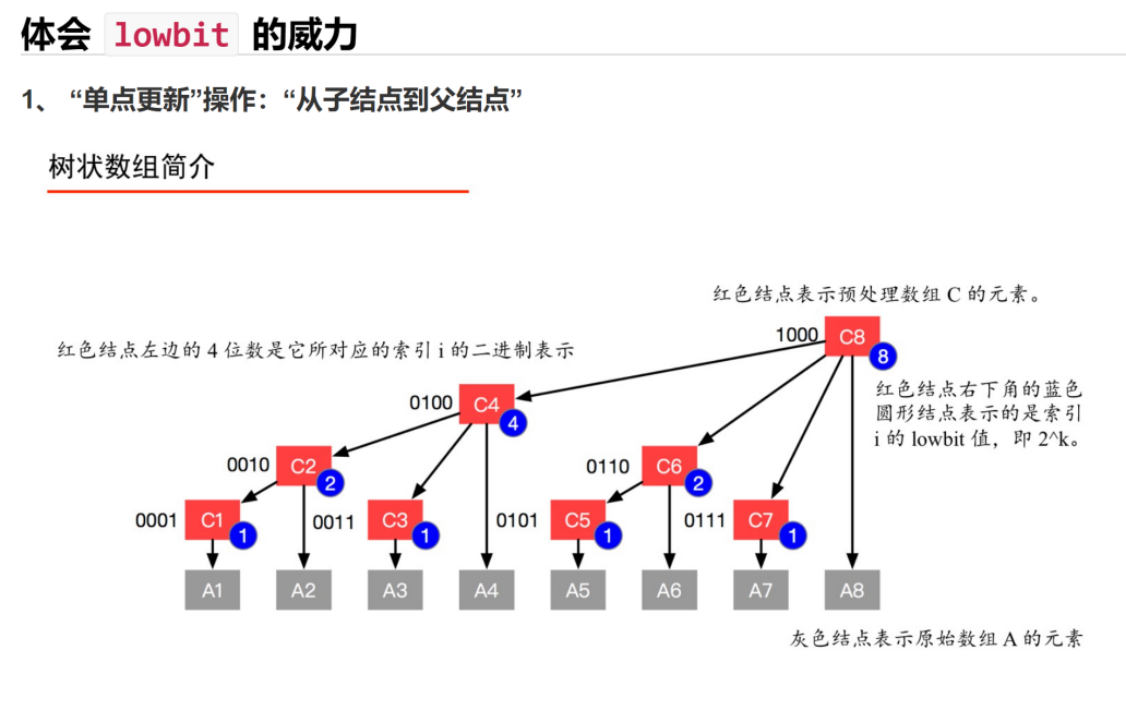
线段树是常用的维护区间信息的数据结构
(1)单点修改
(2)区间修改
(3)区间查询(区间求和,求区间max,求区间min,区间gcd等等)
(1)每个节点表示一个区间
(2)root node表示区间为[1, n]
(3)leaf Node表示区间为[x, x]
(4)线段树中如果一个节点区间为[l, r](l != r)那么这个节点的左子树的根表示区间为[l, mid],这个节点的右子树的根表示区间就是[mid + 1, r], 其中mid = Floor((l + r) /2)
(1)每个节点表示一个区间
(2)root node表示区间为[1, n]
(3)leaf Node表示区间为[x, x]
(4)线段树中如果一个节点区间为[l, r](l != r)那么这个节点的左子树的根表示区间为[l, mid],这个节点的右子树的根表示区间就是[mid + 1, r], 其中mid = Floor((l + r) /2)
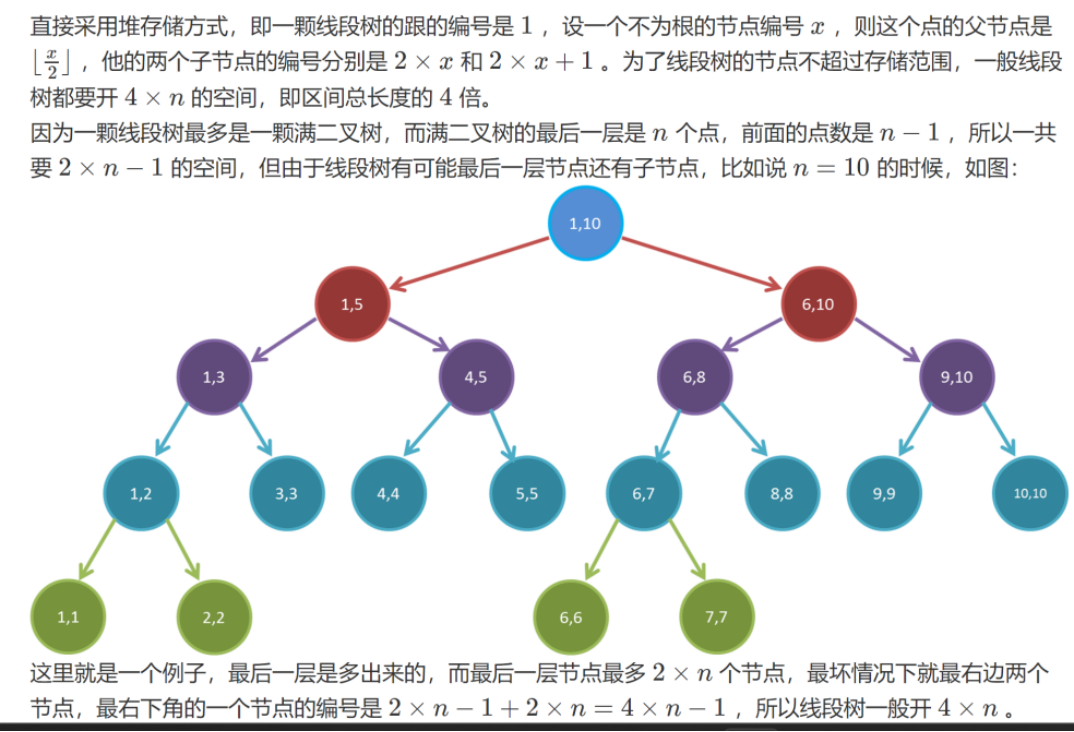
时间复杂度为O(n)
1 | struct Segment_Tree { |
时间复杂度均为O(logN)
1 | void modify (int u,int x,tag_type d) { |
思路1:
时间复杂度均为O(N)
1 | void modify (int u,int l,int r,tag_type d) { |
思路2:
1 | void push_down (int u) { //下传标记函数 |
1 | LL query_sum (int u,int l,int r) { |
参考:线段树 acwing


1 | /** |

1 | /** |