ASCII字符集
总共128个字符,包括一些不可见字符
ISO 8859-1 字符集(latin1)
共收录256个字符,是在ASCII字符集的基础上又扩充了128个西欧常用字符(包括德法两国的字母),也可以使用1个字节来进行编码。
GB2312字符集
收录了汉字以及拉丁字母,希腊字母 收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母。其中收录汉字6763个,其他文字符号682个。同时这种字符集又兼容ASCII字符集,所以在编码方式上显得有些奇怪:
1.如果该字符在ASCII字符集中,则采用1字节编码
2.否则采用2字节编码
GBK字符集
GBK字符集只是在收录字符范围上对GB2312字符集作了扩充,编码方式上兼容GB2312
utf8字符集
收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容ASCII字符集,采用变长编码方式,编码一个字符需要使用1~4个字节
其实准确的说,utf8只是Unicode字符集的一种编码方案,Unicode字符集可以采用utf8、utf16、utf32这几种编码方案,utf8使用1~4个字节编码一个字符,utf16使用2个或4个字节编码一个字符,utf32使用4个字节编码一个字符。更详细的Unicode和其编码方案的知识不是本书的重点,大家上网查查。MySQL中并不区分字符集和编码方案的概念,所以后边介绍的时候把utf8、utf16、utf32都当作一种字符集对待。
MySQL中支持的字符集和排序规则
MySQL中的utf8和utf8mb4
- utf8mb3:阉割过的utf8字符集,只使用1~3个字节表示字符。
- utf8mb4:正宗的utf8字符集,使用1~4个字节表示字符。
MySQL字符集的查看
1 | SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式]; |
MySQL比较规则的查看
1 | SHOW COLLATION [LIKE 匹配的模式]; |
各个级别的字符集和比较规则
服务器级别
MySQL提供了两个系统变量来表示服务器级别的字符集和比较规则:
服务器级别默认的字符集是utf8,默认的比较规则是utf8_general_ci
可以用以下命令查看:1
SHOW VARIABLES LIKE [匹配模式]
数据库级别
我们在创建和修改数据库的时候可以指定该数据库的字符集和比较规则1
2
3
4
5
6
7CREATE DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];
ALTER DATABASE 数据库名
[[DEFAULT] CHARACTER SET 字符集名称]
[[DEFAULT] COLLATE 比较规则名称];如果想查看当前数据库使用的字符集和比较规则,可以查看下面两个系统变量的值(前提是使用USE语句选择当前默认数据库,如果没有默认数据库,则变量与相应的服务器级系统变量具有相同的值):

表级别
我们也可以在创建和修改表的时候指定表的字符集和比较规则,语法如下:1
2
3
4
5
6
7CREATE TABLE 表名 (列的信息)
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]
ALTER TABLE 表名
[[DEFAULT] CHARACTER SET 字符集名称]
[COLLATE 比较规则名称]列级别
需要注意的是,对于存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则。我们在创建和修改列定义的时候可以指定该列的字符集和比较规则,语法如下:1
2
3
4
5
6
7CREATE TABLE 表名(
列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称],
其他列...
);
ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];对于某个列来说,如果在创建和修改的语句中没有指明字符集和比较规则,将使用该列所在表的字符集和比较规则作为该列的字符集和比较规则。
小贴士:在转换列的字符集时需要注意,如果转换前列中存储的数据不能用转换后的字符集进行表示,就会发生错误。比方说原先列使用的字符集是utf8,列中存储了一些汉字,现在把列的字符集转换为ascii的话就会出错,因为ascii字符集并不能表示汉字字符。
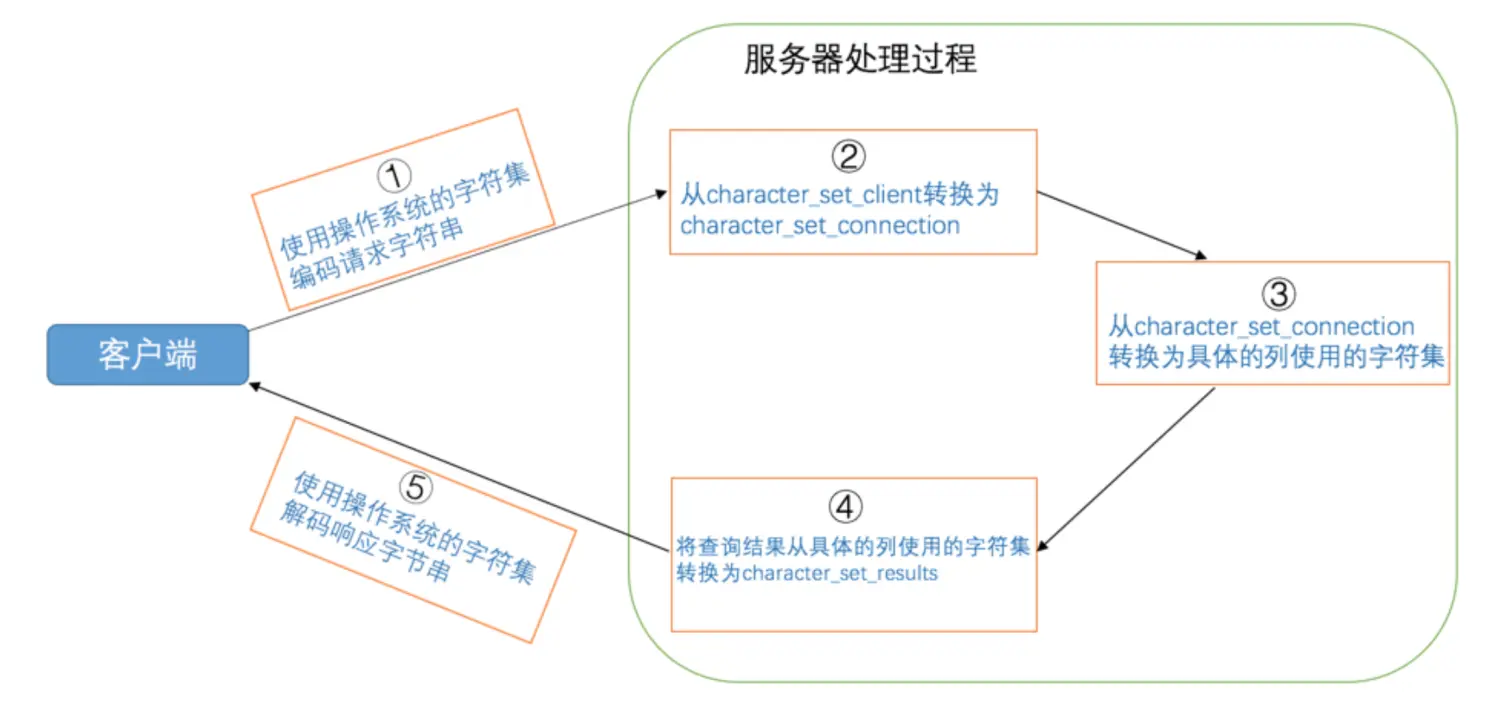
MySQL中字符集的转换
我们知道从客户端发往服务器的请求本质上就是一个字符串,服务器向客户端返回的结果本质上也是一个字符串,而字符串其实是使用某种字符集编码的二进制数据。