正规方程
正规方程是通过求解下面的方程来找出使得代价最小的函数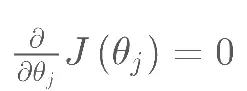
只适用于线性模型,不适合逻辑回归模型等其它模型
过拟合、欠拟合、权重衰退
训练误差和泛化误差
训练误差:模型在训练数据集上计算得到的误差
泛化误差:模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望
我们永远不能准确地计算出泛化误差。这是因为无限多地数据样本是一个虚构的对象。在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的、未曾在训练集中出现的数据样本构成
模型复杂度
几个倾向于影响模型泛化的因素
1.可调整参数的数量。当可调整参数的数量(自由度)很大时,模型往往更容易过拟合
2.参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合
3.训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型
正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度