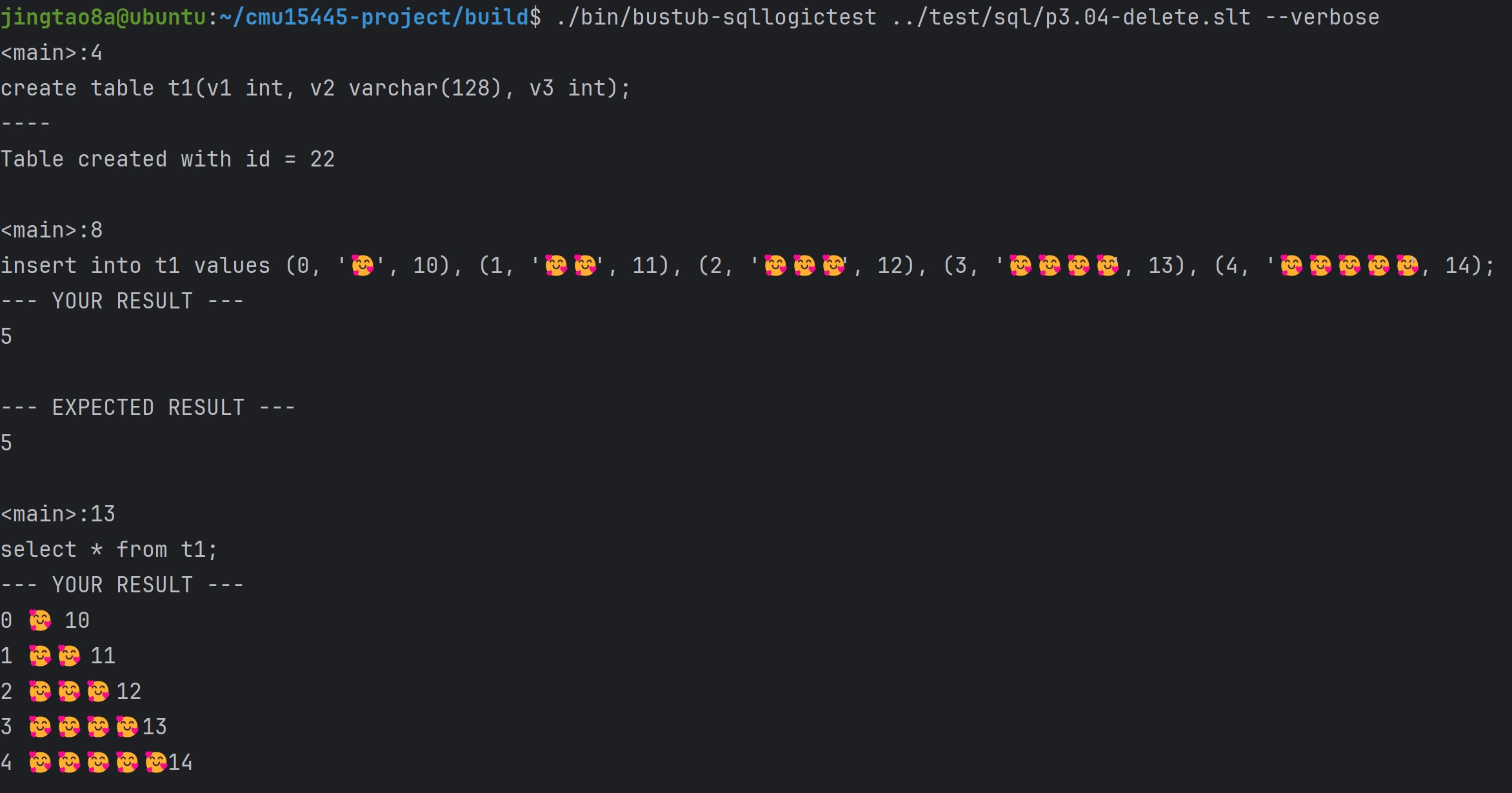
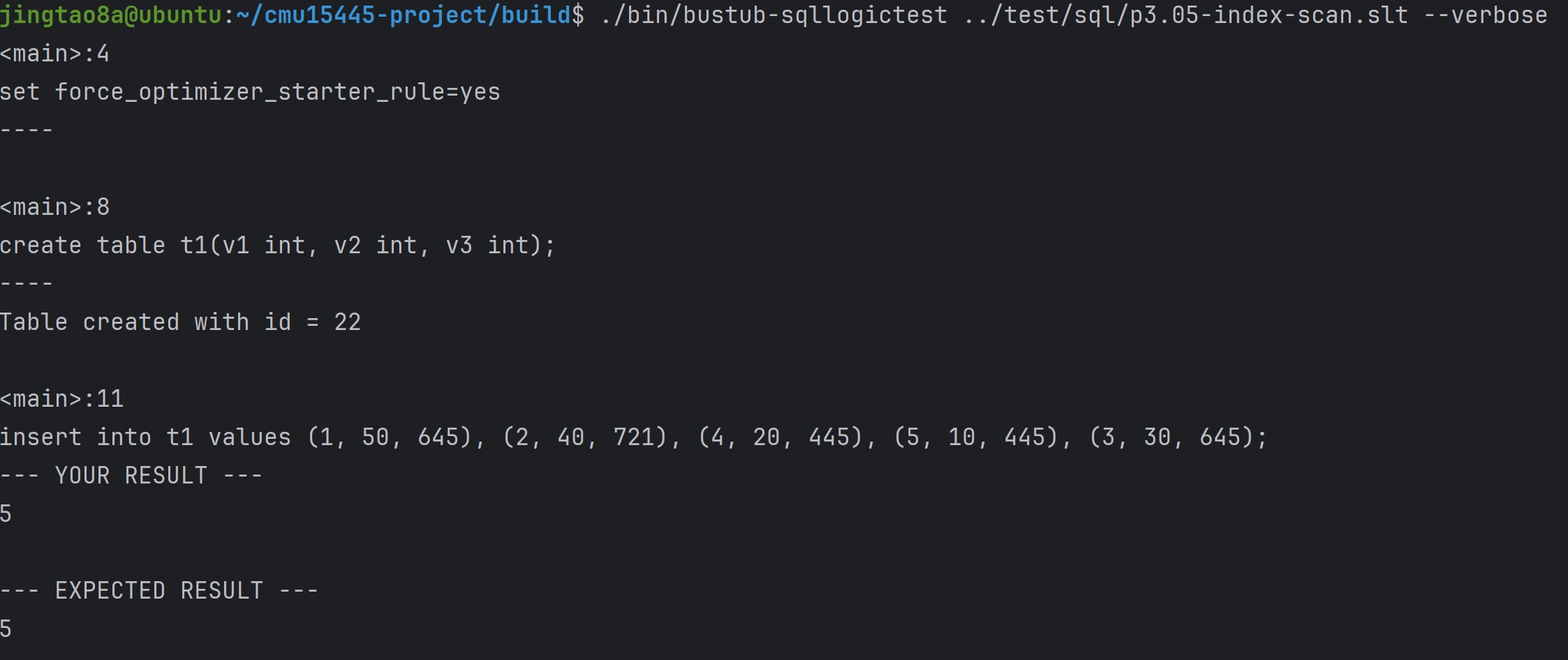
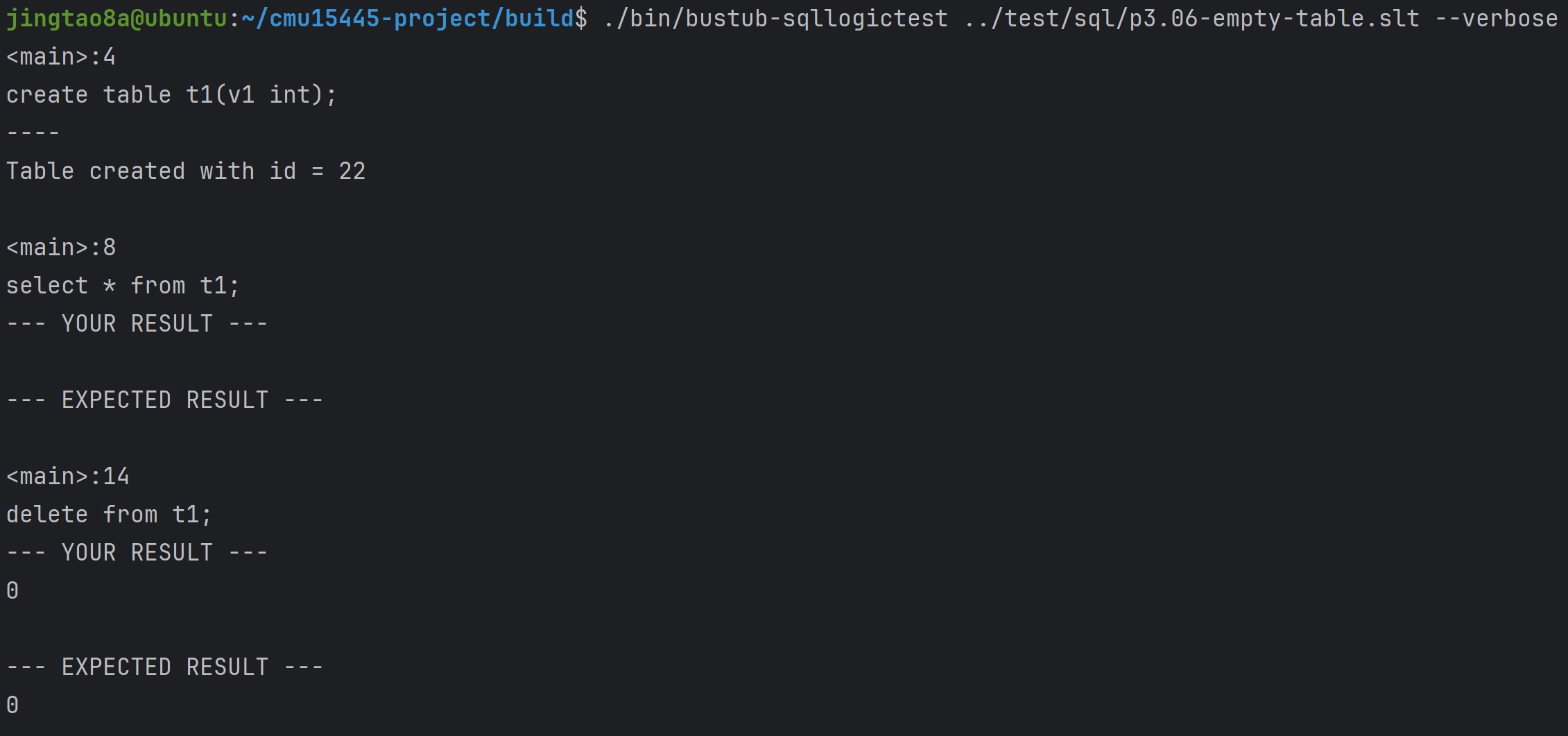
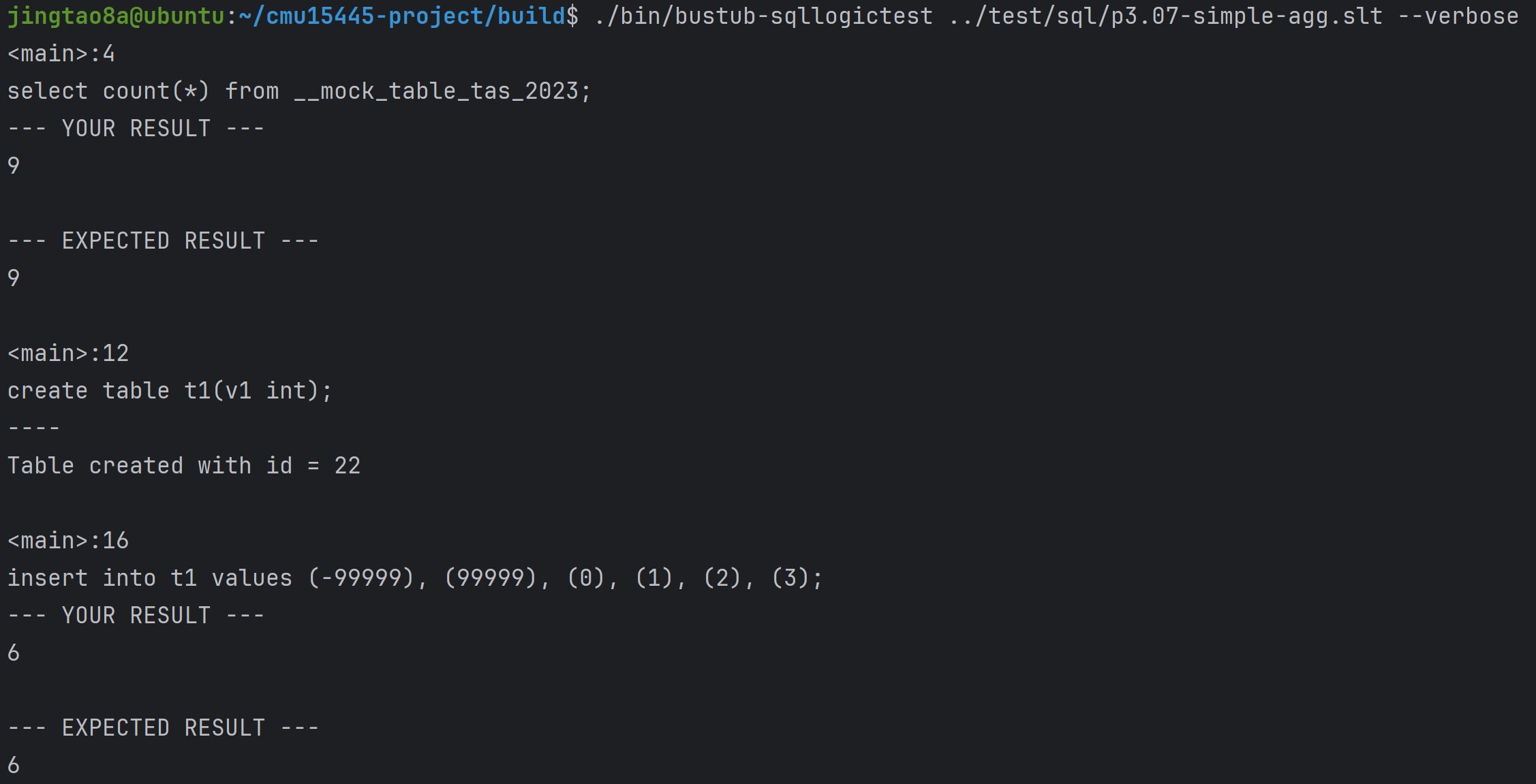
Query Processing Model OLAP与OLTP数据库
OLAP数据库架构将数据读取优先于数据写入操作。可以快速地对大量数据执行复杂的查询
OLTP数据库架构将数据写入优先于数据读取操作。它针对写入密集型工作负载进行了优化
example:
使用OLTP数据库实时处理交易、更新库存水平和管理客户账户
使用OLAP数据库来分析有关销售趋势、库存水平、客户人口统计等
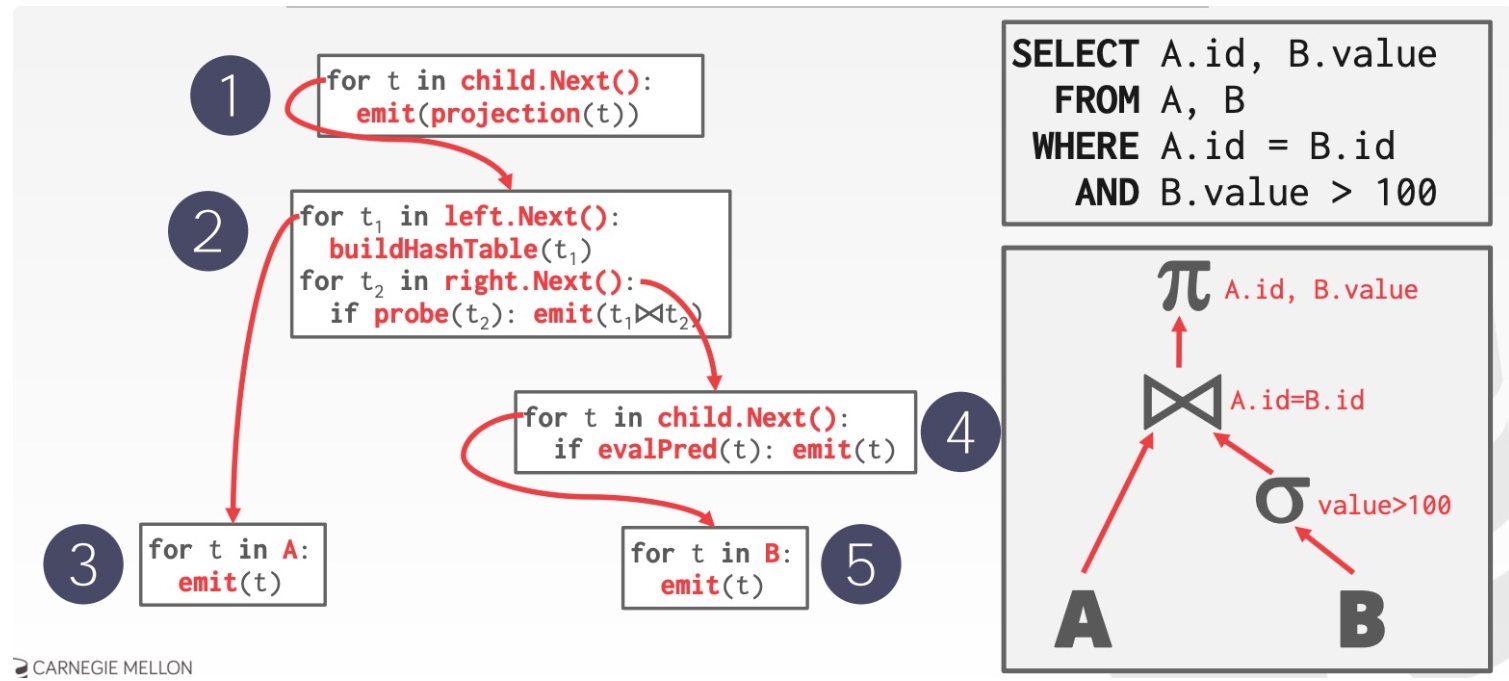
DBMS的Processing Model定义了系统如何执行一个query plan,目前主要有三种模型
Iterator Model
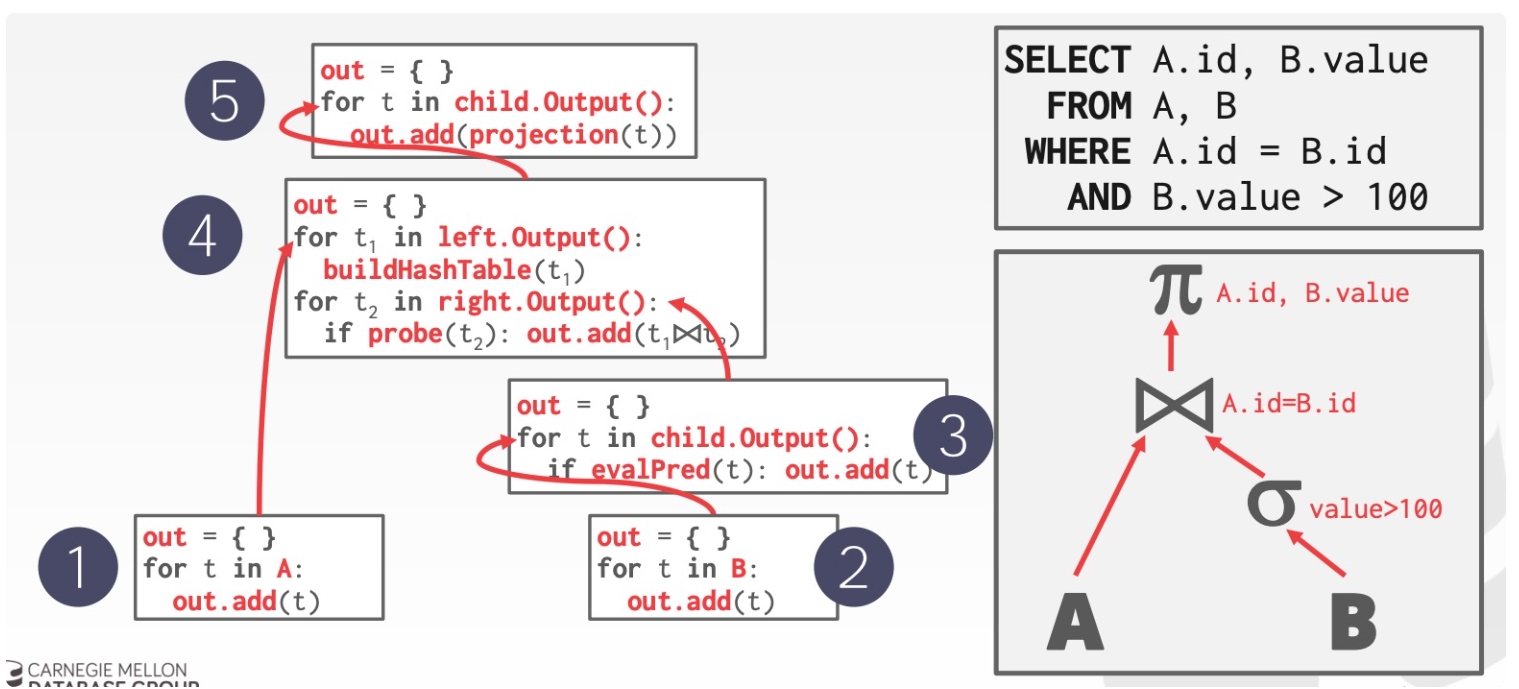
Materialization Model
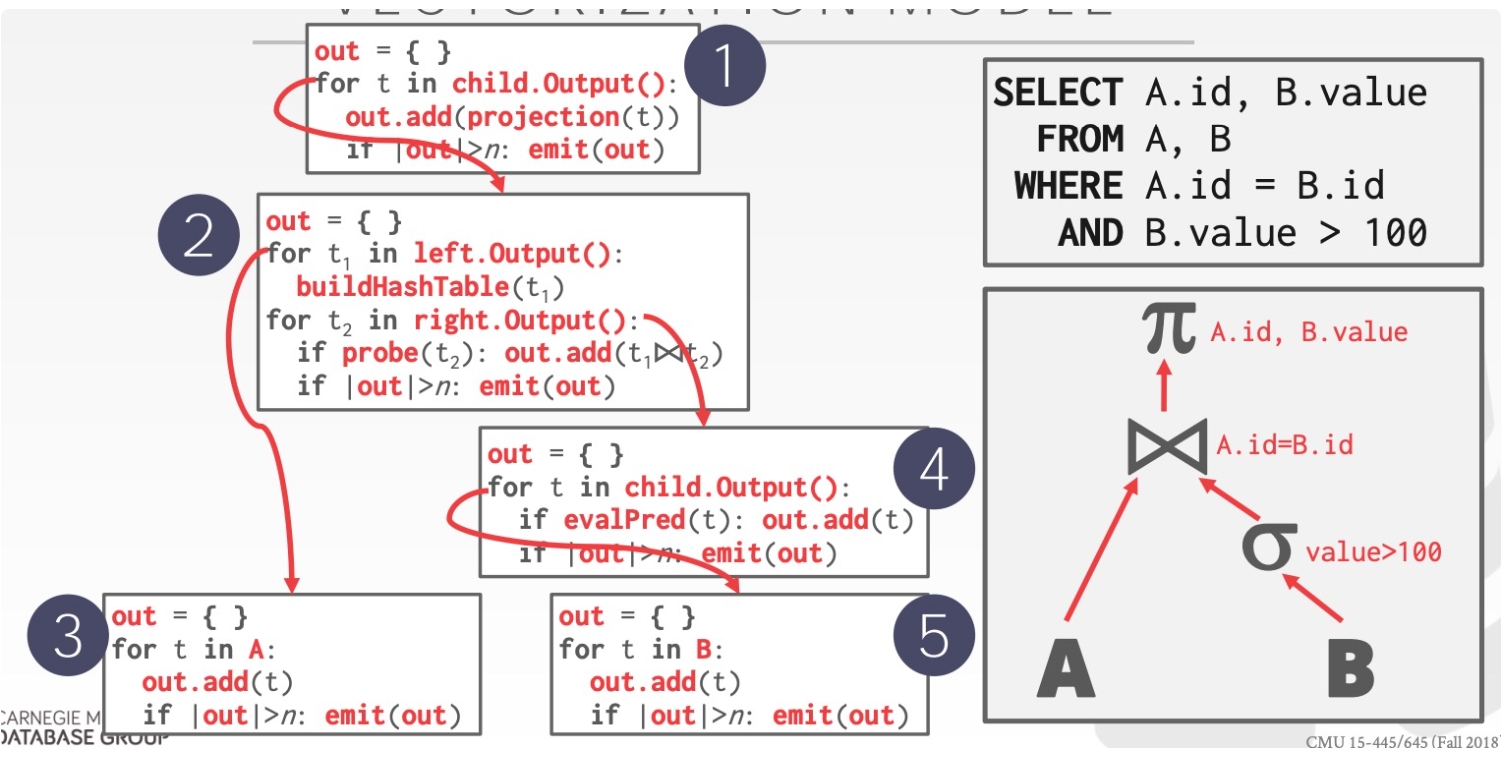
Vectorized/Batch Model
Iterator Model query plan 中的每步 operator 都实现一个 next 函数,每次调用时,operator 返回一个 tuple 或者 null,后者表示数据已经遍历完毕。operator 本身实现一个循环,每次调用其 child operators 的 next 函数,从它们那边获取下一条数据供自己操作,这样整个 query plan 就被从上至下地串联起来,它也称为 Volcano/Pipeline Model:
有些 operators 会等待 children 返回所有 tuples 后才执行,如 Joins, Subqueries 和 Order By
Output Control 在 Iterator Model 中比较容易,如 Limit,只按需调用 next 即可
Materialization Model 每个 operator 处理完所有输入后,将所有结果一次性输出,DBMS 会将一些参数传递到 operator 中防止处理过多的数据,这是一种从下至上的思路,示意如下:
更适合 OLTP 场景,因为后者通常指需要处理少量的 tuples,这样能减少不必要的执行、调度成本
不太适合会产生大量中间结果的 OLAP 查询
Vectorization Model Vectorization Model 是 Iterator 与 Materialization Model 折衷的一种模型:
每个 operator 实现一个 next 函数,但每次 next 调用返回一批 tuples,而不是单个 tuple
operator 内部的循环每次也是一批一批 tuples 地处理
batch 的大小可以根据需要改变(hardware、query properties)
vectorization model 是 OLAP 查询的理想模型:
极大地减少每个 operator 的调用次数
允许 operators 使用 vectorized instructions (SIMD) 来批量处理 tuples
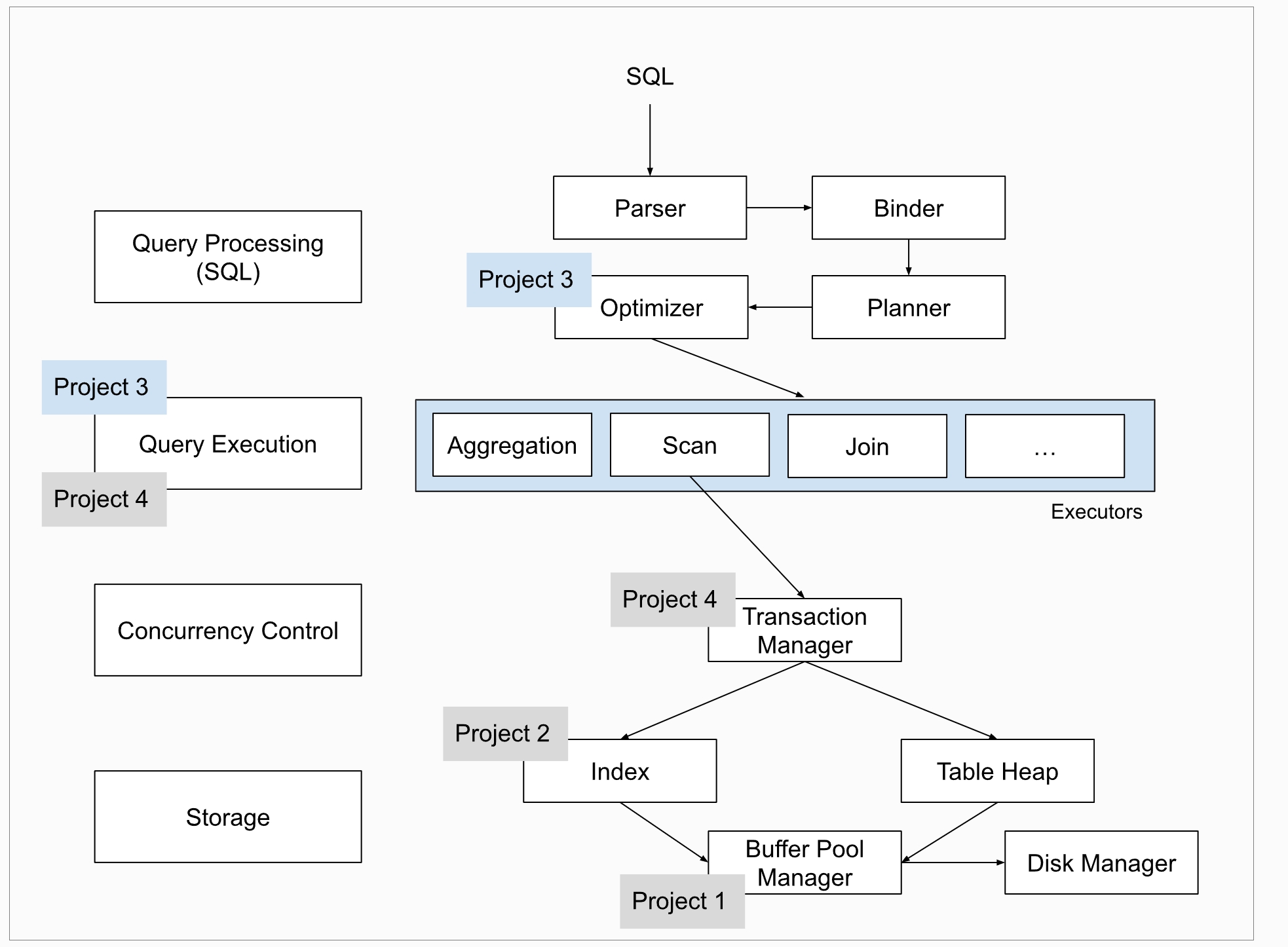
BACKGROUND:QUERY PROCESSING BusTub架构如下
note:
BusTub只支持SQL的一个小子集,可以通过tests/sql中的SQLLogicTest文件来查看它所支持的SQL语句
如果你使用Clion来运行Bustub shell,添加–disable-tty参数
SQL语句使用;结尾
BusTub只支持INT和VARCHAR(n)类型,字符串使用单引号
Bustub使用Iterator Porcessing Model
Inspecting SQL query plans BusTub支持EXPLAIN来打印SQL查询计划
Task#1 Access Method Executors 我们并不需要关心query plan是如何创建的;但有必要理解query plan的组成结构:这是棵树,每个plan节点都对应具体的算子,Bustub采用iterator procesing model,也就是Top-to-Bottom的火山模型,因此query plan的执行就是从根节点开始,将plan节点转换为对应的算子
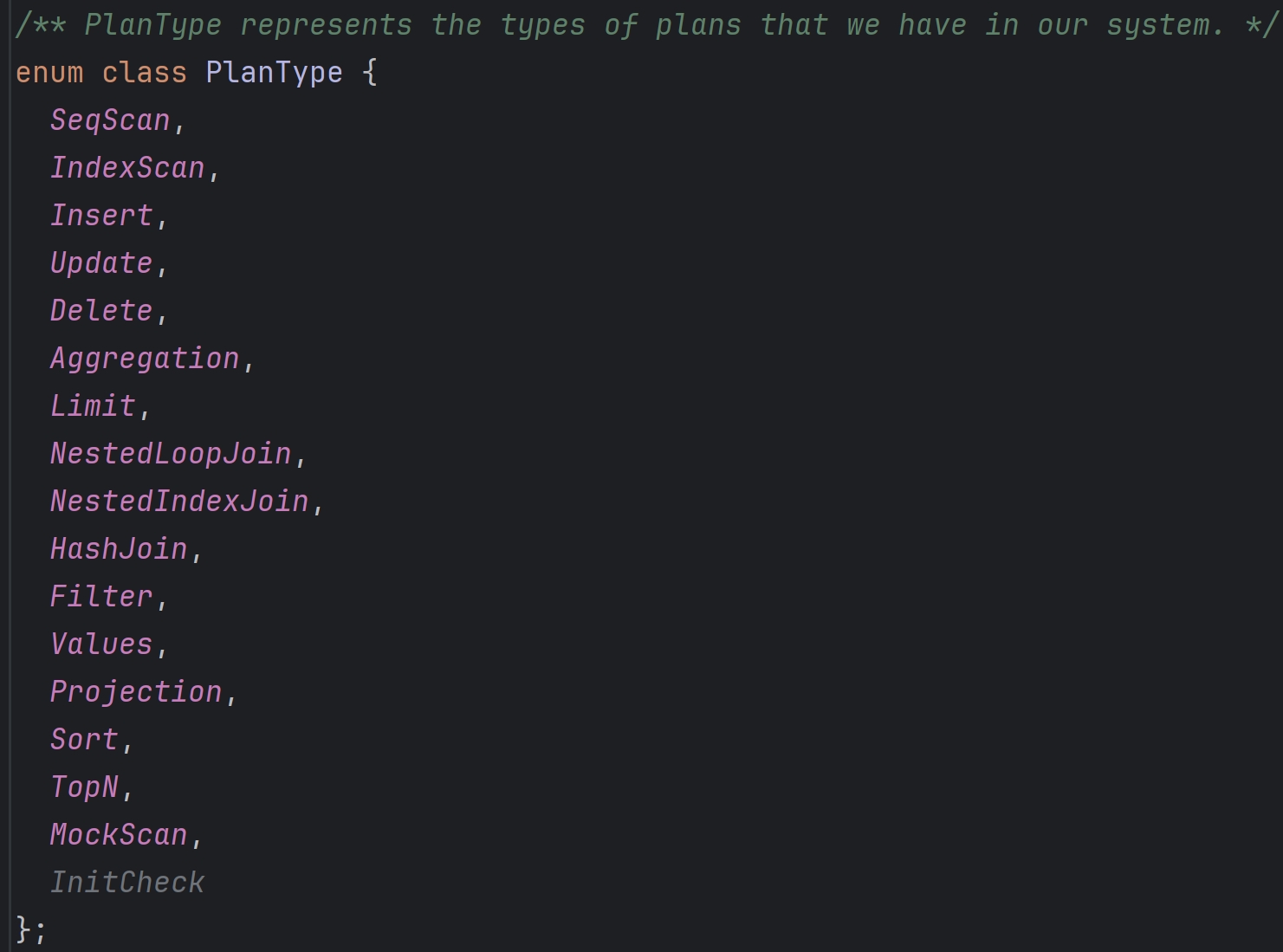
Plan节点的类型如下
表Table的元信息
其中TableHeap代表磁盘上的一张表,是一个doubly-linked of pages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct TableInfo { Schema schema_; const std::string name_; std::unique_ptr<TableHeap> table_; const table_oid_t oid_; }; class TableHeap { page_id_t first_page_id_{INVALID_PAGE_ID}; page_id_t last_page_id_{INVALID_PAGE_ID}; };
索引Index的元信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct IndexInfo { Schema key_schema_; std::string name_; std::unique_ptr<Index> index_; index_oid_t index_oid_; std::string table_name_; const size_t key_size_; };
catalog
记录所有TableInfo和IndexInfo
1 2 3 4 5 6 7 8 9 10 class Catalog { std::unordered_map<table_oid_t , std::unique_ptr<TableInfo>> tables_; std::unordered_map<std::string, table_oid_t > table_names_; std::unordered_map<index_oid_t , std::unique_ptr<IndexInfo>> indexes_; std::unordered_map<std::string, std::unordered_map<std::string, index_oid_t >> index_names_; };
SeqScanExecutor实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class SeqScanExecutor { const SeqScanPlanNode *plan_; TableInfo *table_info_; std::unique_ptr<TableIterator> iterator_; }; void SeqScanExecutor::Init () auto catalog = exec_ctx_->GetCatalog (); table_info_ = catalog->GetTable (plan_->table_oid_); iterator_ = std::make_unique <TableIterator>(table_info_->table_->MakeIterator ()); } auto SeqScanExecutor::Next (Tuple *tuple, RID *rid) -> bool std::pair<TupleMeta, Tuple> pair; while (!iterator_->IsEnd ()) { pair = iterator_->GetTuple (); if (pair.first.is_deleted_) { ++(*iterator_); continue ; } if (plan_->filter_predicate_) { auto res = plan_->filter_predicate_->Evaluate (&pair.second, table_info_->schema_); if (!(!res.IsNull () && res.GetAs <bool >())) { ++(*iterator_); continue ; } } ++(*iterator_); *tuple = std::move (pair.second); *rid = tuple->GetRid (); return true ; } return false ; }
InsertExecutor实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class InsertExecutor { const InsertPlanNode *plan_; bool successful_; TableInfo *table_info_; std::vector<IndexInfo *> index_infos_; std::unique_ptr<AbstractExecutor> child_executor_; }; void InsertExecutor::Init () child_executor_->Init (); auto cata_log = exec_ctx_->GetCatalog (); table_info_ = cata_log->GetTable (plan_->table_oid_); index_infos_ = cata_log->GetTableIndexes (table_info_->name_); successful_ = false ; } auto InsertExecutor::Next (Tuple *tuple, RID *rid) -> bool TupleMeta meta; if (successful_) { return false ; } meta.insert_txn_id_ = INVALID_TXN_ID; meta.delete_txn_id_ = INVALID_TXN_ID; meta.is_deleted_ = false ; auto count = 0 ; while (child_executor_->Next (tuple, rid)) { auto tuple_rid = table_info_->table_->InsertTuple (meta, *tuple, exec_ctx_->GetLockManager (), exec_ctx_->GetTransaction (), table_info_->oid_); if (tuple_rid == std::nullopt ) { continue ; } for (auto index_info : index_infos_) { auto key = tuple->KeyFromTuple (table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs ()); index_info->index_->InsertEntry (key, *tuple_rid, exec_ctx_->GetTransaction ()); } ++count; } std::vector<Value> values; values.emplace_back (TypeId::INTEGER, count); *tuple = Tuple (values, &GetOutputSchema ()); successful_ = true ; return true ; }
UpdateExecutor实现
这里实现的思路就是将旧的Tuple删除,插入新的Tuple
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class UpdateExecutor { const UpdatePlanNode *plan_; const TableInfo *table_info_; std::unique_ptr<AbstractExecutor> child_executor_; std::vector<IndexInfo *> index_infos_; bool successful_; }; void UpdateExecutor::Init () child_executor_->Init (); successful_ = false ; auto cata_log = exec_ctx_->GetCatalog (); table_info_ = cata_log->GetTable (plan_->TableOid ()); index_infos_ = cata_log->GetTableIndexes (table_info_->name_); } auto UpdateExecutor::Next (Tuple *tuple, RID *rid) -> bool TupleMeta tuple_meta; if (successful_) { return false ; } tuple_meta.delete_txn_id_ = INVALID_TXN_ID; tuple_meta.insert_txn_id_ = INVALID_TXN_ID; auto count = 0 ; while (child_executor_->Next (tuple, rid)) { tuple_meta.is_deleted_ = true ; table_info_->table_->UpdateTupleMeta (tuple_meta, *rid); for (auto index_info : index_infos_) { auto key = tuple->KeyFromTuple (table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs ()); index_info->index_->DeleteEntry (key, *rid, exec_ctx_->GetTransaction ()); } std::vector<Value> values; for (auto &expresssion : plan_->target_expressions_) { values.emplace_back (expresssion->Evaluate (tuple, child_executor_->GetOutputSchema ())); } auto new_tuple = Tuple (values, &child_executor_->GetOutputSchema ()); tuple_meta.is_deleted_ = false ; auto tuple_rid = table_info_->table_->InsertTuple (tuple_meta, new_tuple, exec_ctx_->GetLockManager (), exec_ctx_->GetTransaction (), table_info_->oid_); if (tuple_rid == std::nullopt ) { continue ; } for (auto index_info : index_infos_) { auto key = new_tuple.KeyFromTuple (table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs ()); index_info->index_->InsertEntry (key, *tuple_rid, exec_ctx_->GetTransaction ()); } ++count; } std::vector<Value> values; values.emplace_back (TypeId::INTEGER, count); *tuple = {values, &GetOutputSchema ()}; successful_ = true ; return true ; }
DeleteExecutor实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class DeleteExecutor { const DeletePlanNode *plan_; std::unique_ptr<AbstractExecutor> child_executor_; bool successful_; TableInfo *table_info_; std::vector<IndexInfo *> index_infos_; }; void DeleteExecutor::Init () child_executor_->Init (); successful_ = false ; auto catalog = exec_ctx_->GetCatalog (); table_info_ = catalog->GetTable (plan_->TableOid ()); index_infos_ = catalog->GetTableIndexes (table_info_->name_); } auto DeleteExecutor::Next (Tuple *tuple, RID *rid) -> bool TupleMeta tuple_meta; if (successful_) { return false ; } tuple_meta.delete_txn_id_ = INVALID_TXN_ID; tuple_meta.insert_txn_id_ = INVALID_TXN_ID; tuple_meta.is_deleted_ = true ; auto count = 0 ; while (child_executor_->Next (tuple, rid)) { table_info_->table_->UpdateTupleMeta (tuple_meta, *rid); for (auto index_info : index_infos_) { auto key = tuple->KeyFromTuple (table_info_->schema_, index_info->key_schema_, index_info->index_->GetKeyAttrs ()); index_info->index_->DeleteEntry (key, *rid, exec_ctx_->GetTransaction ()); } count++; } std::vector<Value> values; values.emplace_back (TypeId::INTEGER, count); *tuple = Tuple (values, &GetOutputSchema ()); successful_ = true ; return true ; }
IndexScanExecutor实现 SELECT FROM
ORDER BY 中的ORDER BY会被转为IndexScan
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class IndexScanExecutor { const IndexScanPlanNode *plan_; IndexInfo *index_info_; TableInfo *table_info_; BPlusTreeIndexForTwoIntegerColumn *index_; std::unique_ptr<BPlusTreeIndexIteratorForTwoIntegerColumn> index_iterator_; }; void IndexScanExecutor::Init () auto catalog = exec_ctx_->GetCatalog (); index_info_ = catalog->GetIndex (plan_->index_oid_); table_info_ = catalog->GetTable (index_info_->table_name_); index_ = dynamic_cast <BPlusTreeIndexForTwoIntegerColumn *>(index_info_->index_.get ()); index_iterator_ = std::make_unique <BPlusTreeIndexIteratorForTwoIntegerColumn>(index_->GetBeginIterator ()); } auto IndexScanExecutor::Next (Tuple *tuple, RID *rid) -> bool while (!index_iterator_->IsEnd ()) { auto map = *(*index_iterator_); *rid = map.second; if (!table_info_->table_->GetTupleMeta (*rid).is_deleted_) { index_iterator_->operator ++(); *tuple = table_info_->table_->GetTuple (*rid).second; return true ; } index_iterator_->operator ++(); } return false ; }
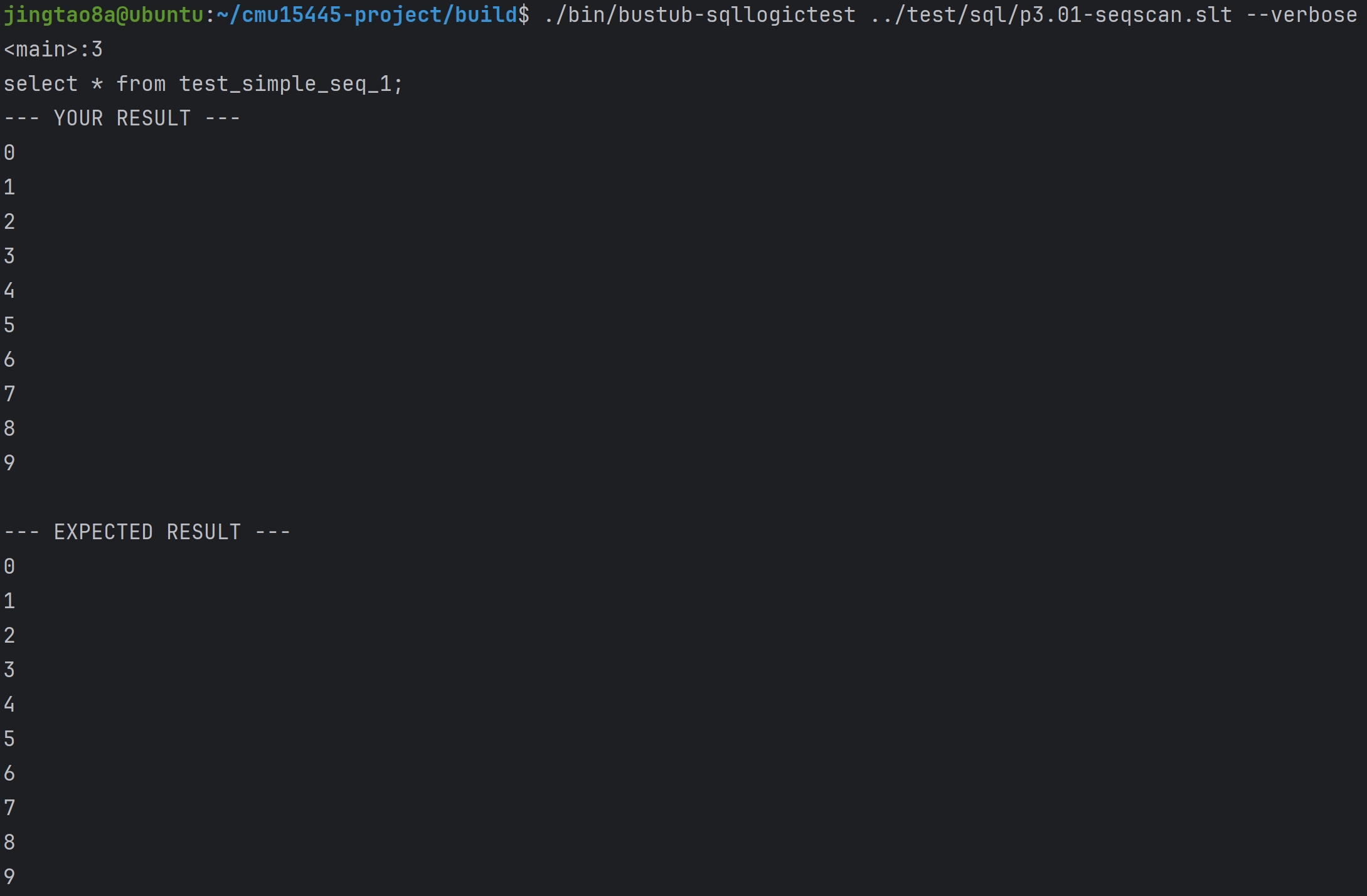
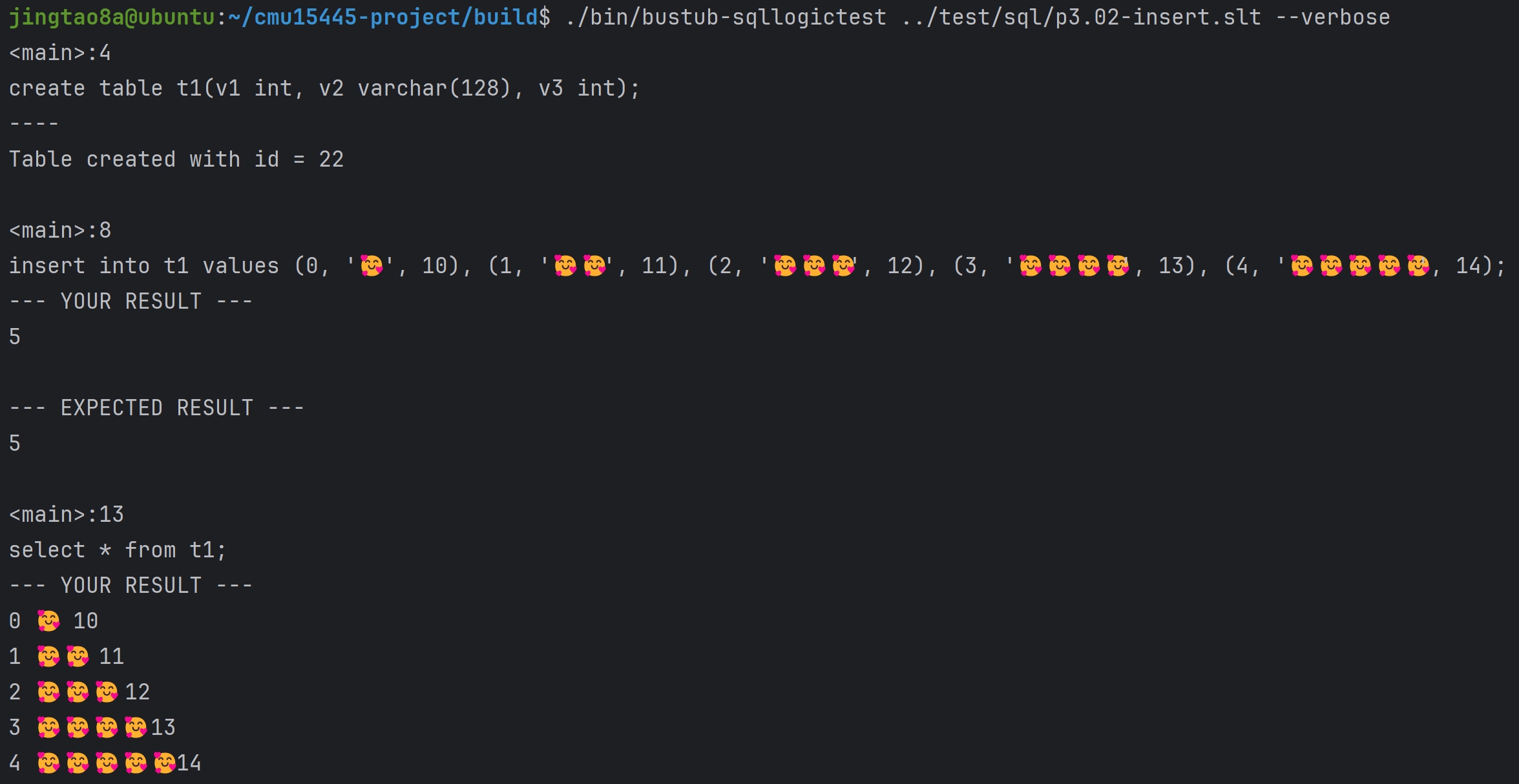
这里通过SQLLogicTests#1 to #6
Task#2 Aggregation & Join Executors AggregationExecutor实现
AggregationExecutor用来支持以下的sql查询,第四条sql语句的DISTINCT相当于GROUP BY
补充完成SimpleAggregationHashTable,其中哈希表的键AggregateKey就是GROUP BY的columns
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 class SimpleAggregationHashTable {private : std::unordered_map<AggregateKey, AggregateValue> ht_{}; const std::vector<AbstractExpressionRef> &agg_exprs_; const std::vector<AggregationType> &agg_types_; public : auto GenerateInitialAggregateValue () -> AggregateValue std::vector<Value> values{}; for (const auto &agg_type : agg_types_) { switch (agg_type) { case AggregationType::CountStarAggregate: values.emplace_back (ValueFactory::GetIntegerValue (0 )); break ; case AggregationType::CountAggregate: case AggregationType::SumAggregate: case AggregationType::MinAggregate: case AggregationType::MaxAggregate: values.emplace_back (ValueFactory::GetNullValueByType (TypeId::INTEGER)); break ; } } return {values}; } void CombineAggregateValues (AggregateValue *result, const AggregateValue &input) for (uint32_t i = 0 ; i < agg_exprs_.size (); i++) { switch (agg_types_[i]) { case AggregationType::CountStarAggregate: result->aggregates_[i] = {INTEGER, result->aggregates_[i].GetAs <int32_t >() + 1 }; break ; case AggregationType::CountAggregate: if (input.aggregates_[i].IsNull ()) { break ; } if (result->aggregates_[i].IsNull ()) { result->aggregates_[i] = {INTEGER, 1 }; } else { result->aggregates_[i] = {INTEGER, result->aggregates_[i].GetAs <int32_t >() + 1 }; } break ; case AggregationType::SumAggregate: if (input.aggregates_[i].IsNull ()) { break ; } if (result->aggregates_[i].IsNull ()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Add ((input.aggregates_[i])); } break ; case AggregationType::MinAggregate: if (input.aggregates_[i].IsNull ()) { break ; } if (result->aggregates_[i].IsNull ()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Min (input.aggregates_[i]); } break ; case AggregationType::MaxAggregate: if (input.aggregates_[i].IsNull ()) { break ; } if (result->aggregates_[i].IsNull ()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Max (input.aggregates_[i]); } break ; } } } void InsertCombine (const AggregateKey &agg_key, const AggregateValue &agg_val) if (ht_.count (agg_key) == 0 ) { ht_.insert ({agg_key, GenerateInitialAggregateValue ()}); } CombineAggregateValues (&ht_[agg_key], agg_val); } void Insert (const AggregateKey &agg_key, const AggregateValue &agg_val) insert ({agg_key, agg_val}); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class AggregationExecutor { const AggregationPlanNode *plan_; std::unique_ptr<AbstractExecutor> child_; SimpleAggregationHashTable aht_; std::unique_ptr<SimpleAggregationHashTable::Iterator> aht_iterator_; }; void AggregationExecutor::Init () child_->Init (); Tuple tuple; RID rid; while (child_->Next (&tuple, &rid)) { AggregateKey key = MakeAggregateKey (&tuple); AggregateValue value = MakeAggregateValue (&tuple); aht_.InsertCombine (key, value); } if (aht_.Begin () == aht_.End () && plan_->GetGroupBys ().empty ()) { AggregateKey key; aht_.Insert (key, aht_.GenerateInitialAggregateValue ()); } aht_iterator_ = std::make_unique <SimpleAggregationHashTable::Iterator>(aht_.Begin ()); } auto AggregationExecutor::Next (Tuple *tuple, RID *rid) -> bool if ((*aht_iterator_) == aht_.End ()) { return false ; } auto key = aht_iterator_->Key (); auto value = aht_iterator_->Val (); ++(*aht_iterator_); key.group_bys_.insert (key.group_bys_.end (), value.aggregates_.begin (), value.aggregates_.end ()); *tuple = {key.group_bys_, &GetOutputSchema ()}; return true ; }
NestedLoopJoinExecutor实现 NestedLoopJoinExecutor将支持inner join和left join,使用simple nested loop join算法
NestedLoopJoin是流水线破坏者吗? BusTub采用火山模型(iterator processing
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 class NestedLoopJoinExecutor { const NestedLoopJoinPlanNode *plan_; std::unique_ptr<AbstractExecutor> left_executor_; std::unique_ptr<AbstractExecutor> right_executor_; std::vector<Tuple> right_tuples_; int index_; Tuple left_tuple_; bool is_match_; }; void NestedLoopJoinExecutor::Init () left_executor_->Init (); right_executor_->Init (); Tuple right_tuple; RID right_rid; while (right_executor_->Next (&right_tuple, &right_rid)) { right_tuples_.emplace_back (right_tuple); } index_ = 0 ; is_match_ = false ; } auto NestedLoopJoinExecutor::Next (Tuple *tuple, RID *rid) -> bool RID left_rid; if (index_ != 0 ) { if (NestedLoop (tuple, rid)) { return true ; } } while (left_executor_->Next (&left_tuple_, &left_rid)) { right_executor_->Init (); if (NestedLoop (tuple, rid)) { return true ; } } return false ; } auto NestedLoopJoinExecutor::NestedLoop (Tuple *tuple, RID *rid) -> bool while (index_ < static_cast <int >(right_tuples_.size ())) { if (plan_->predicate_) { auto res = plan_->predicate_->EvaluateJoin (&left_tuple_, left_executor_->GetOutputSchema (), &right_tuples_[index_], right_executor_->GetOutputSchema ()); if (!(!res.IsNull () && res.GetAs <bool >())) { index_++; continue ; } } MergeTuple (tuple); index_ = (index_ + 1 ) % right_tuples_.size (); is_match_ = (index_ != 0 ); return true ; } index_ = 0 ; if (!is_match_ && plan_->GetJoinType () == JoinType::LEFT) { std::vector<Value> values; values.reserve (GetOutputSchema ().GetColumnCount ()); for (auto i = 0 ; i < static_cast <int >(left_executor_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (left_tuple_.GetValue (&left_executor_->GetOutputSchema (), i)); } for (auto i = 0 ; i < static_cast <int >(right_executor_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (ValueFactory::GetNullValueByType (right_executor_->GetOutputSchema ().GetColumn (i).GetType ())); } *tuple = {values, &GetOutputSchema ()}; return true ; } is_match_ = false ; return false ; } void NestedLoopJoinExecutor::MergeTuple (Tuple *tuple) std::vector<Value> values; values.reserve (GetOutputSchema ().GetColumnCount ()); for (auto i = 0 ; i < static_cast <int >(left_executor_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (left_tuple_.GetValue (&left_executor_->GetOutputSchema (), i)); } for (auto i = 0 ; i < static_cast <int >(right_executor_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (right_tuples_[index_].GetValue (&right_executor_->GetOutputSchema (), i)); } *tuple = {values, &GetOutputSchema ()}; }
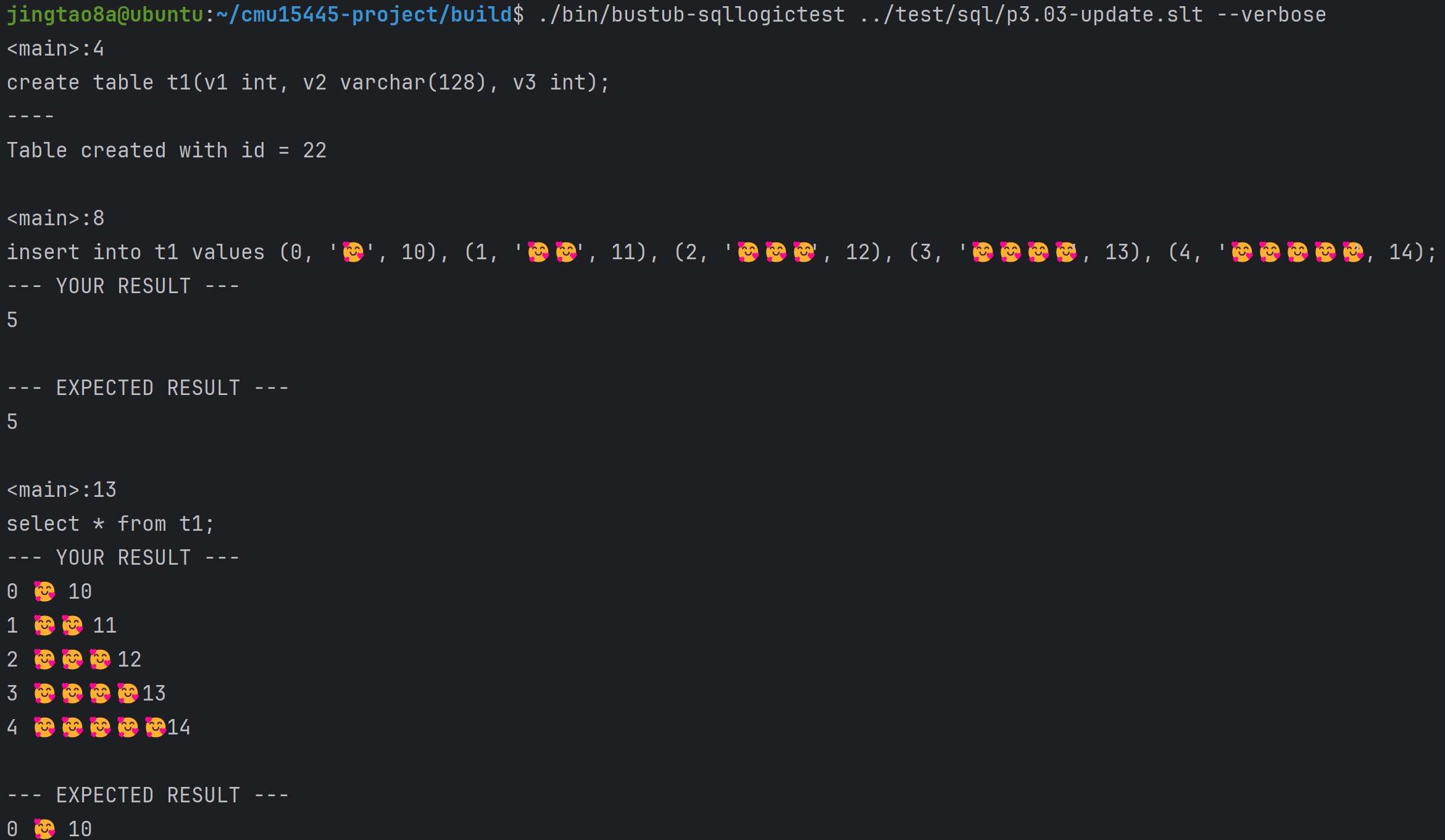
到这里为止,通过SQLLogicTests #7 to #12
HashJoinExecutor实现 你将要为HashJoinExecutor实现inner join和left join,使用hash join算法
实现思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 class HashJoinExecutor { const HashJoinPlanNode *plan_; std::unique_ptr<AbstractExecutor> left_child_; std::unique_ptr<AbstractExecutor> right_child_; std::unordered_map<HashJoinKey, std::vector<Tuple>> map_; std::vector<Tuple> result_; int index_; }; void HashJoinExecutor::Init () left_child_->Init (); right_child_->Init (); Tuple right_tuple; RID right_rid; while (right_child_->Next (&right_tuple, &right_rid)) { HashJoinKey key; for (auto &expression : plan_->RightJoinKeyExpressions ()) { key.column_values_.emplace_back (expression->Evaluate (&right_tuple, right_child_->GetOutputSchema ())); } if (map_.count (key) != 0 ) { map_[key].emplace_back (right_tuple); } else { map_[key] = {right_tuple}; } } Tuple left_tuple; RID left_rid; while (left_child_->Next (&left_tuple, &left_rid)) { HashJoinKey key; for (auto &expression : plan_->LeftJoinKeyExpressions ()) { key.column_values_.emplace_back (expression->Evaluate (&left_tuple, left_child_->GetOutputSchema ())); } if (map_.count (key) != 0 ) { for (auto &t : map_[key]) { std::vector<Value> values; values.reserve (GetOutputSchema ().GetColumnCount ()); for (auto i = 0 ; i < static_cast <int >(left_child_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (left_tuple.GetValue (&left_child_->GetOutputSchema (), i)); } for (auto i = 0 ; i < static_cast <int >(right_child_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (t.GetValue (&right_child_->GetOutputSchema (), i)); } result_.emplace_back (values, &GetOutputSchema ()); } } else if (plan_->GetJoinType () == JoinType::LEFT) { std::vector<Value> values; values.reserve (GetOutputSchema ().GetColumnCount ()); for (auto i = 0 ; i < static_cast <int >(left_child_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (left_tuple.GetValue (&left_child_->GetOutputSchema (), i)); } for (auto i = 0 ; i < static_cast <int >(right_child_->GetOutputSchema ().GetColumnCount ()); ++i) { values.emplace_back (ValueFactory::GetNullValueByType (right_child_->GetOutputSchema ().GetColumn (i).GetType ())); } result_.emplace_back (values, &GetOutputSchema ()); } } index_ = 0 ; } auto HashJoinExecutor::Next (Tuple *tuple, RID *rid) -> bool if (index_ >= static_cast <int >(result_.size ())) { return false ; } *tuple = result_[index_]; index_++; return true ; }
Optimizing NestedLoopJoin to HashJoin 具体来说,当连接谓词是两列之间等条件的合取时,可以使用散列连接算法。就本项目而言,处理单个等值条件以及通过 AND 连接的两个等值条件将获得满分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 auto Optimizer::OptimizeNLJAsHashJoin (const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef std::vector<AbstractPlanNodeRef> children; for (auto &child : plan->GetChildren ()) { children.emplace_back (OptimizeNLJAsHashJoin (child)); } auto optimized_plan = plan->CloneWithChildren (std::move (children)); if (optimized_plan->GetType () == PlanType::NestedLoopJoin) { const auto nlj_plan = dynamic_cast <const NestedLoopJoinPlanNode &>(*optimized_plan); BUSTUB_ENSURE (nlj_plan.children_.size () == 2 , "NLJ should have exactly 2 children." ); if (auto *expr = dynamic_cast <ComparisonExpression *>(nlj_plan.Predicate ().get ()); expr != nullptr ) { if (expr->comp_type_ == ComparisonType::Equal) { if (auto *left_expr = dynamic_cast <ColumnValueExpression *>(expr->children_[0 ].get ()); left_expr != nullptr ) { if (auto *right_expr = dynamic_cast <ColumnValueExpression *>(expr->children_[1 ].get ()); right_expr != nullptr ) { std::vector<AbstractExpressionRef> left_key_expressions; std::vector<AbstractExpressionRef> right_key_expressions; if (left_expr->GetTupleIdx () == 0 && right_expr->GetTupleIdx () == 1 ) { left_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(0 , left_expr->GetColIdx (), left_expr->GetReturnType ())); right_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(1 , right_expr->GetColIdx (), right_expr->GetReturnType ())); } else if (left_expr->GetTupleIdx () == 1 && right_expr->GetTupleIdx () == 0 ) { left_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(0 , right_expr->GetColIdx (), right_expr->GetReturnType ())); right_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(1 , left_expr->GetColIdx (), left_expr->GetReturnType ())); } return std::make_shared <HashJoinPlanNode>(nlj_plan.output_schema_, nlj_plan.GetLeftPlan (), nlj_plan.GetRightPlan (), std::move (left_key_expressions), std::move (right_key_expressions), nlj_plan.GetJoinType ()); } } } } if (auto *expr = dynamic_cast <LogicExpression *>(nlj_plan.Predicate ().get ()); expr != nullptr ) { if (expr->logic_type_ == LogicType::And) { BUSTUB_ASSERT (expr->GetChildren ().size () == 2 , "LogicExpression has two children" ); if (auto *expr1 = dynamic_cast <ComparisonExpression *>(expr->children_[0 ].get ()); expr1 != nullptr ) { if (auto *expr2 = dynamic_cast <ComparisonExpression *>(expr->children_[1 ].get ()); expr2 != nullptr ) { if (expr1->comp_type_ == ComparisonType::Equal && expr2->comp_type_ == ComparisonType::Equal) { std::vector<AbstractExpressionRef> left_key_expressions; std::vector<AbstractExpressionRef> right_key_expressions; if (auto *left_expr = dynamic_cast <ColumnValueExpression *>(expr1->children_[0 ].get ()); left_expr != nullptr ) { if (auto *right_expr = dynamic_cast <ColumnValueExpression *>(expr1->children_[1 ].get ()); right_expr != nullptr ) { if (left_expr->GetTupleIdx () == 0 && right_expr->GetTupleIdx () == 1 ) { left_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(0 , left_expr->GetColIdx (), left_expr->GetReturnType ())); right_key_expressions.emplace_back (std::make_shared <ColumnValueExpression>( 1 , right_expr->GetColIdx (), right_expr->GetReturnType ())); } else if (left_expr->GetTupleIdx () == 1 && right_expr->GetTupleIdx () == 0 ) { left_key_expressions.emplace_back (std::make_shared <ColumnValueExpression>( 0 , right_expr->GetColIdx (), right_expr->GetReturnType ())); right_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(1 , left_expr->GetColIdx (), left_expr->GetReturnType ())); } } } if (auto *left_expr = dynamic_cast <ColumnValueExpression *>(expr2->children_[0 ].get ()); left_expr != nullptr ) { if (auto *right_expr = dynamic_cast <ColumnValueExpression *>(expr2->children_[1 ].get ()); right_expr != nullptr ) { if (left_expr->GetTupleIdx () == 0 && right_expr->GetTupleIdx () == 1 ) { left_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(0 , left_expr->GetColIdx (), left_expr->GetReturnType ())); right_key_expressions.emplace_back (std::make_shared <ColumnValueExpression>( 1 , right_expr->GetColIdx (), right_expr->GetReturnType ())); } else if (left_expr->GetTupleIdx () == 1 && right_expr->GetTupleIdx () == 0 ) { left_key_expressions.emplace_back (std::make_shared <ColumnValueExpression>( 0 , right_expr->GetColIdx (), right_expr->GetReturnType ())); right_key_expressions.emplace_back ( std::make_shared <ColumnValueExpression>(1 , left_expr->GetColIdx (), left_expr->GetReturnType ())); } } } return std::make_shared <HashJoinPlanNode>(nlj_plan.output_schema_, nlj_plan.GetLeftPlan (), nlj_plan.GetRightPlan (), std::move (left_key_expressions), std::move (right_key_expressions), nlj_plan.GetJoinType ()); } } } } } } return optimized_plan; }
到这里为止,通过SQLLogicTests #14 to #15
Task#3 Sort + Limit Executors and Top-N Optimization SortExecutor实现: 如果查询的ORDER BY属性与索引的key不匹配,BusTub将为查询生成一个SortPlanNode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class SortExecutor { const SortPlanNode *plan_; std::unique_ptr<AbstractExecutor> child_executor_; std::vector<Tuple> result_; int index_; }; void SortExecutor::Init () Tuple tuple; RID rid; child_executor_->Init (); while (child_executor_->Next (&tuple, &rid)) { result_.emplace_back (tuple); } std::sort (result_.begin (), result_.end (), [this ](const Tuple &left, const Tuple &right) -> bool { return this ->TupleComparator (left, right); }); index_ = 0 ; } auto SortExecutor::Next (Tuple *tuple, RID *rid) -> bool if (index_ >= static_cast <int >(result_.size ())) { return false ; } *tuple = result_[index_]; index_++; return true ; } auto SortExecutor::TupleComparator (const Tuple &left, const Tuple &right) -> bool auto &order_by = plan_->GetOrderBy (); for (auto &p : order_by) { auto order = p.first; auto &exp = p.second; auto lvalue = exp->Evaluate (&left, child_executor_->GetOutputSchema ()); auto rvalue = exp->Evaluate (&right, child_executor_->GetOutputSchema ()); if (order == OrderByType::DESC) { if (lvalue.CompareGreaterThan (rvalue) == CmpBool::CmpTrue) { return true ; } if (lvalue.CompareLessThan (rvalue) == CmpBool::CmpTrue) { return false ; } } else { if (lvalue.CompareLessThan (rvalue) == CmpBool::CmpTrue) { return true ; } if (lvalue.CompareGreaterThan (rvalue) == CmpBool::CmpTrue) { return false ; } } } UNREACHABLE ("duplicate key is not allowed" ); }
LimitExecutor实现: LimitExectutor限制其子executor的输出tuple数量。如果其子executor生成的元组数量小于LimitExecutor中指定的限制,则该executor无效并生成它接受到的所有tuple
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class LimitExecutor { const LimitPlanNode *plan_; std::unique_ptr<AbstractExecutor> child_executor_; size_t num_; }; void LimitExecutor::Init () child_executor_->Init (); num_ = 0 ; } auto LimitExecutor::Next (Tuple *tuple, RID *rid) -> bool if (num_ >= plan_->GetLimit ()) { return false ; } if (child_executor_->Next (tuple, rid)) { num_++; return true ; } return false ; }
Top-N Optimization Rule 用一个优先队列维护top n 条tuple
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class TopNExecutor { const TopNPlanNode *plan_; std::unique_ptr<AbstractExecutor> child_executor_; std::priority_queue<HeapKeyType> heap_; std::deque<Tuple> result_; }; void TopNExecutor::Init () child_executor_->Init (); Tuple tuple; RID rid; while (child_executor_->Next (&tuple, &rid)) { HeapKeyType key (tuple, plan_->GetOrderBy(), child_executor_.get()) ; heap_.emplace (tuple, plan_->GetOrderBy (), child_executor_.get ()); if (heap_.size () > plan_->GetN ()) { heap_.pop (); } } while (!heap_.empty ()) { result_.emplace_front (heap_.top ().tuple_); heap_.pop (); } } auto TopNExecutor::Next (Tuple *tuple, RID *rid) -> bool if (GetNumInHeap () != 0 ) { *tuple = result_.front (); result_.pop_front (); return true ; } return false ; } auto TopNExecutor::GetNumInHeap () -> size_t return result_.size (); }
到这里为止,通过SQLLogicTests #16 to #19
通过线上测试: