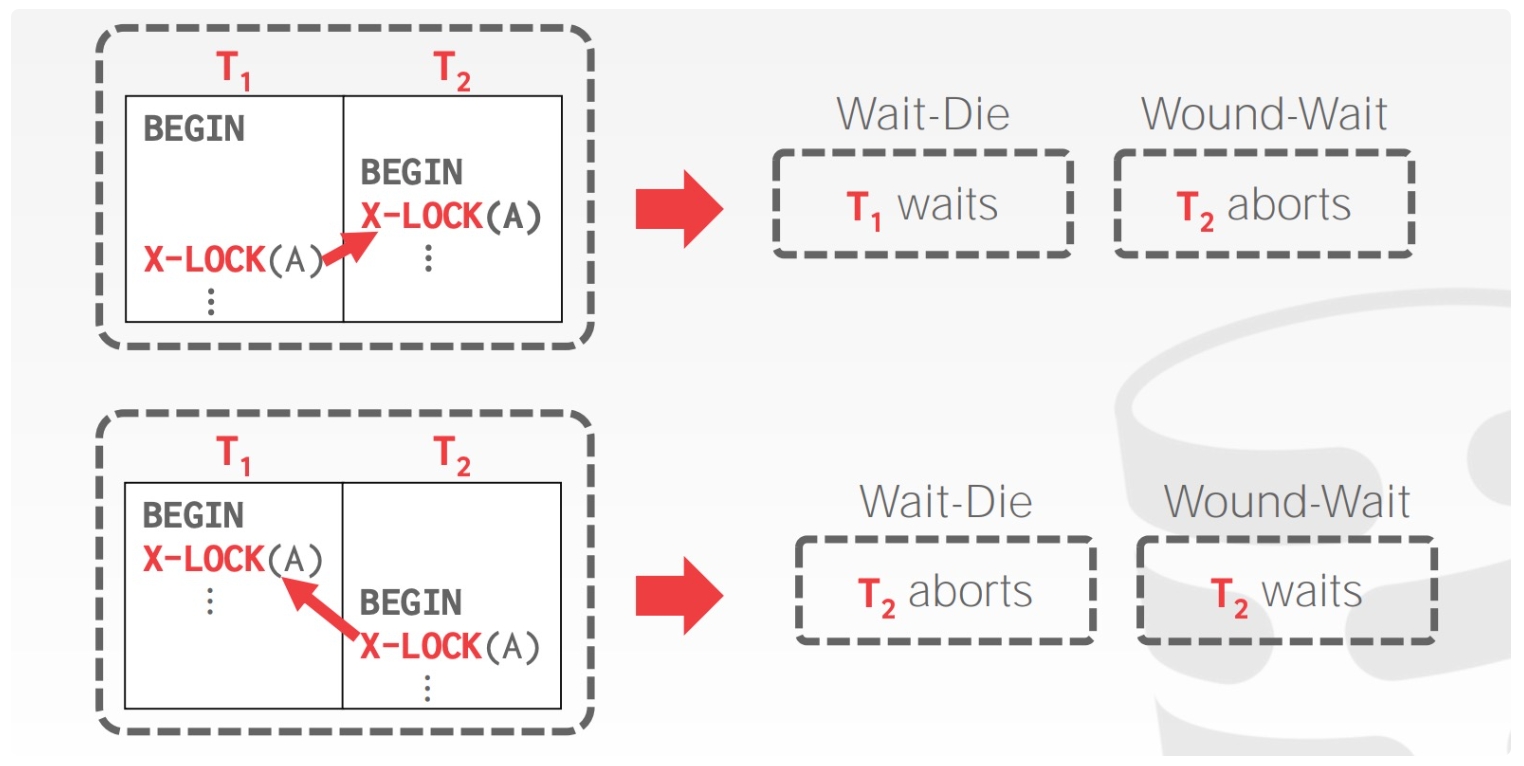
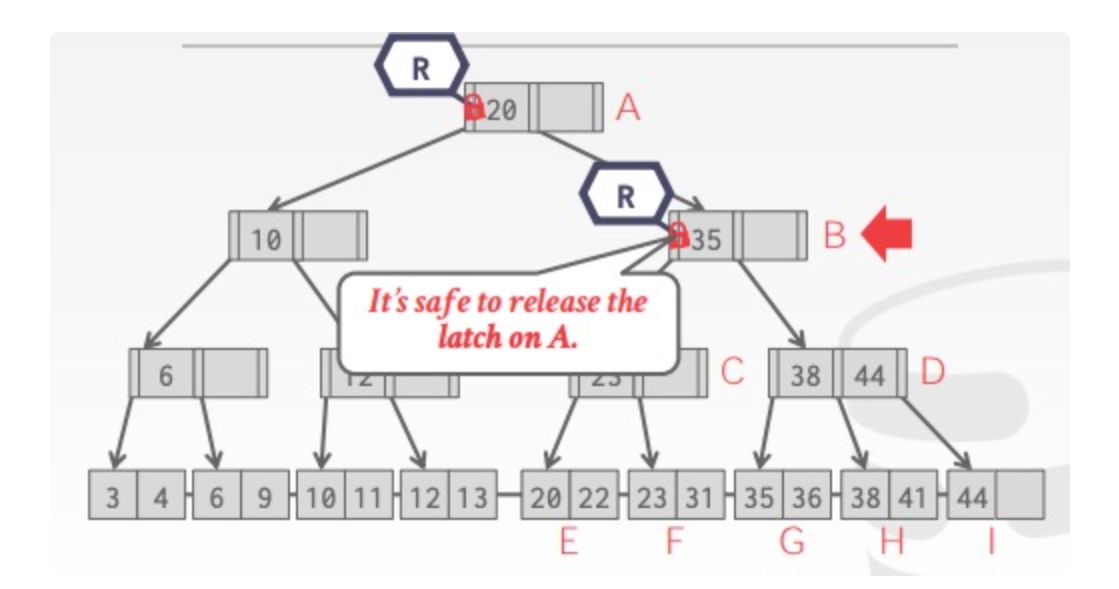
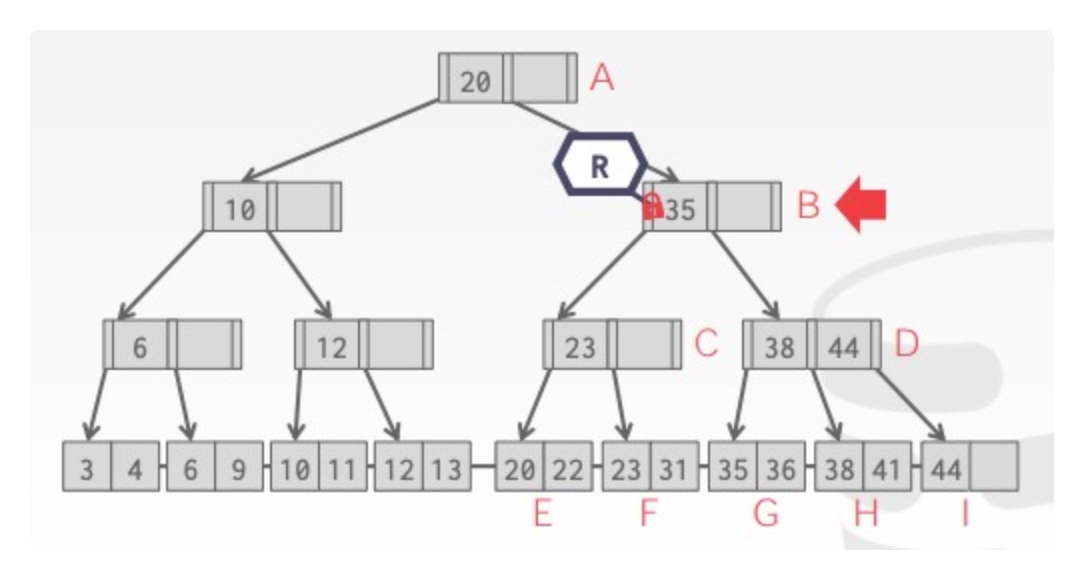
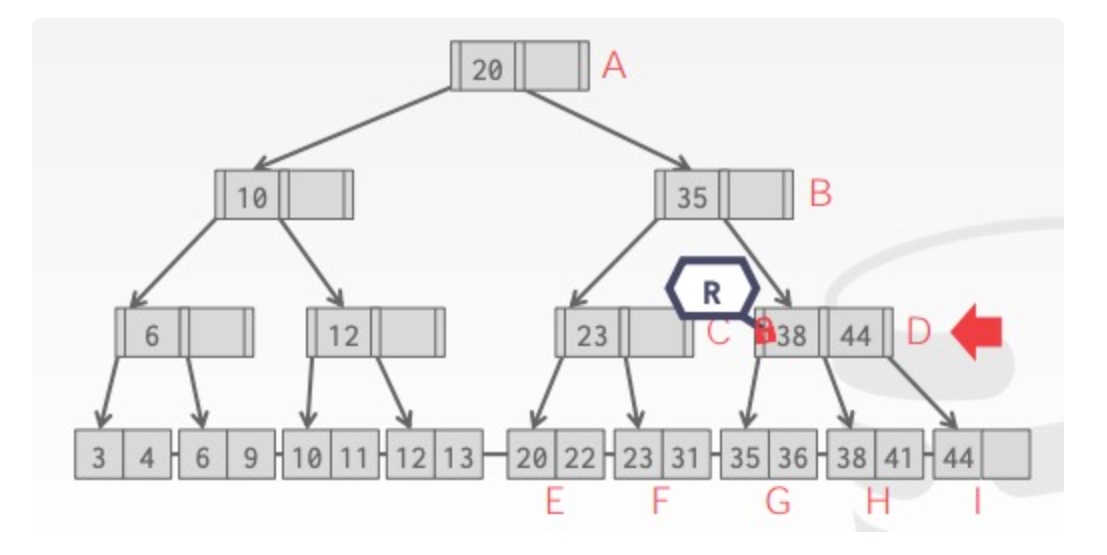
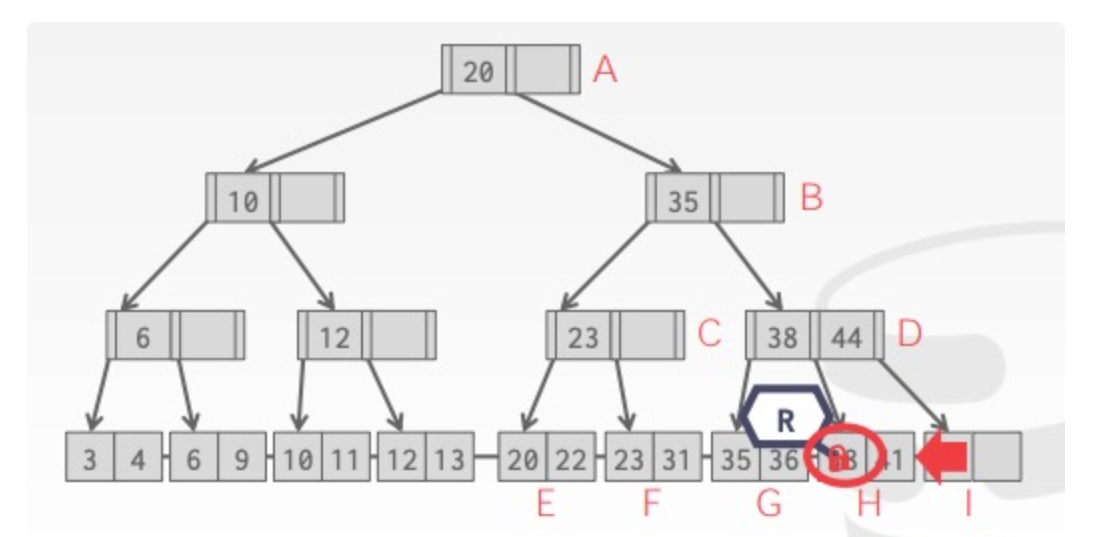
Old Waits for Young:如果 requesting txn 优先级比 holding txn 更高则等待后者释放锁;更低则自行中止
Young Waits for Old:如果 requesting txn 优先级比 holding txn 更高则后者自行中止释放锁,让前者获取锁,否则 requesting txn 等待 holding txn 释放锁
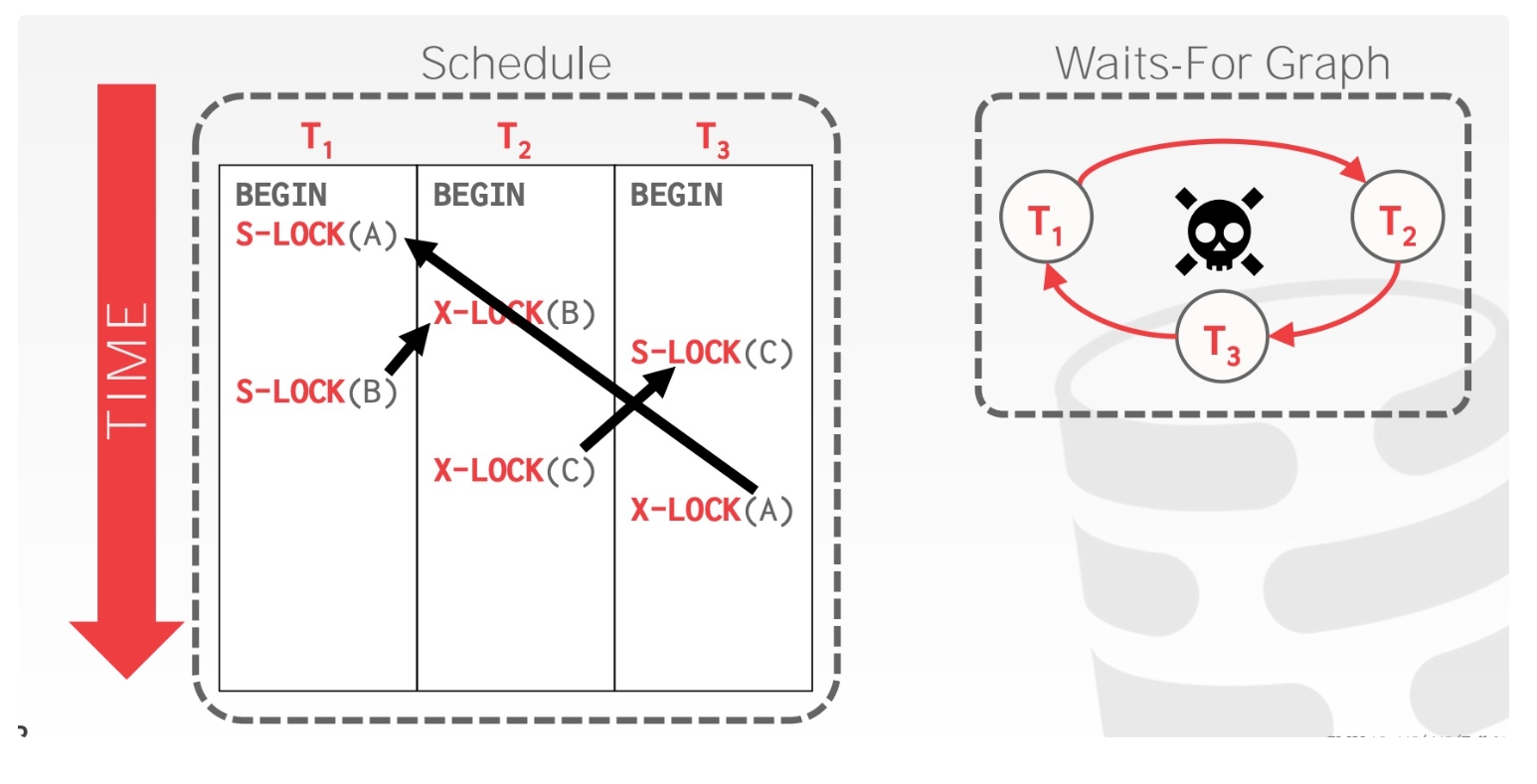
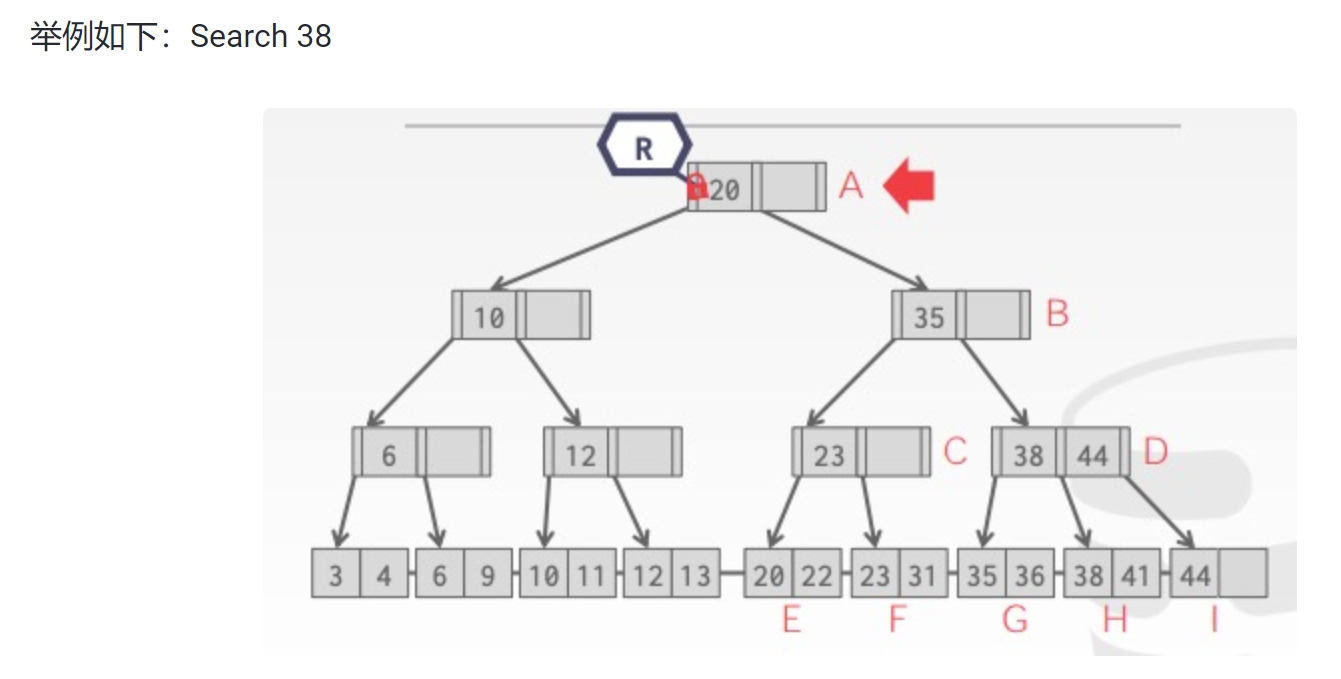
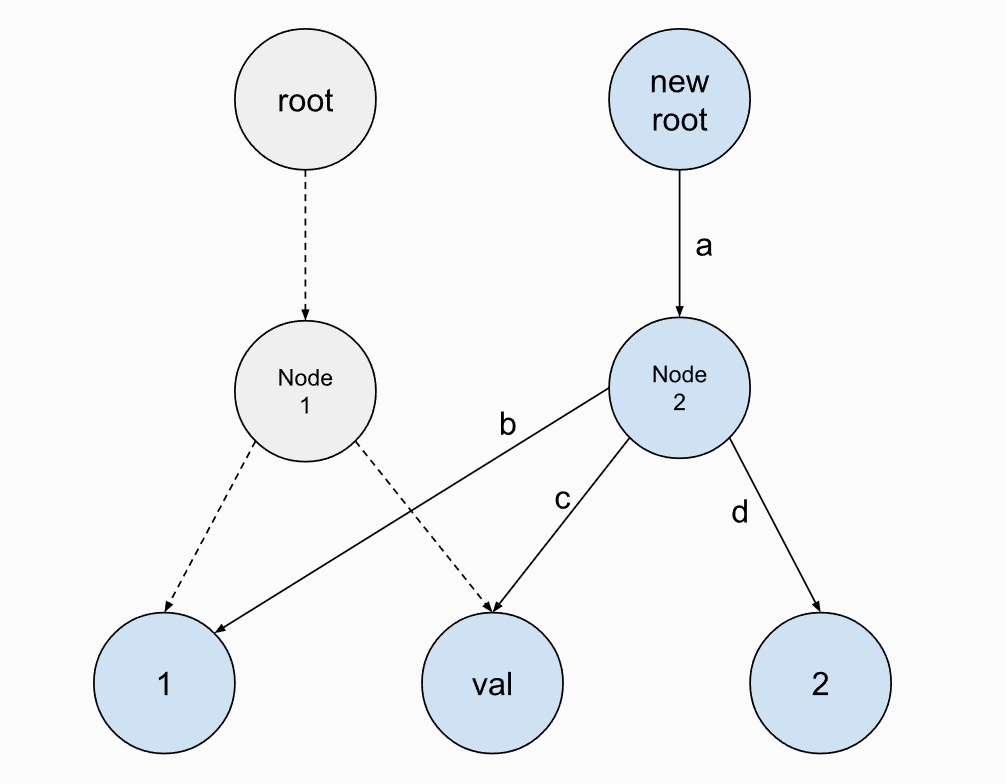
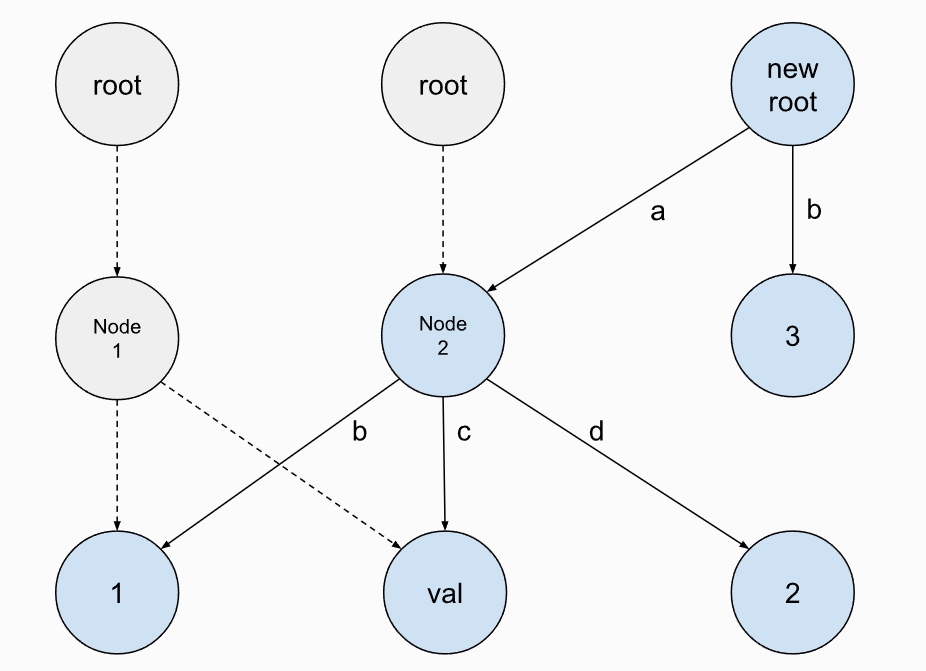
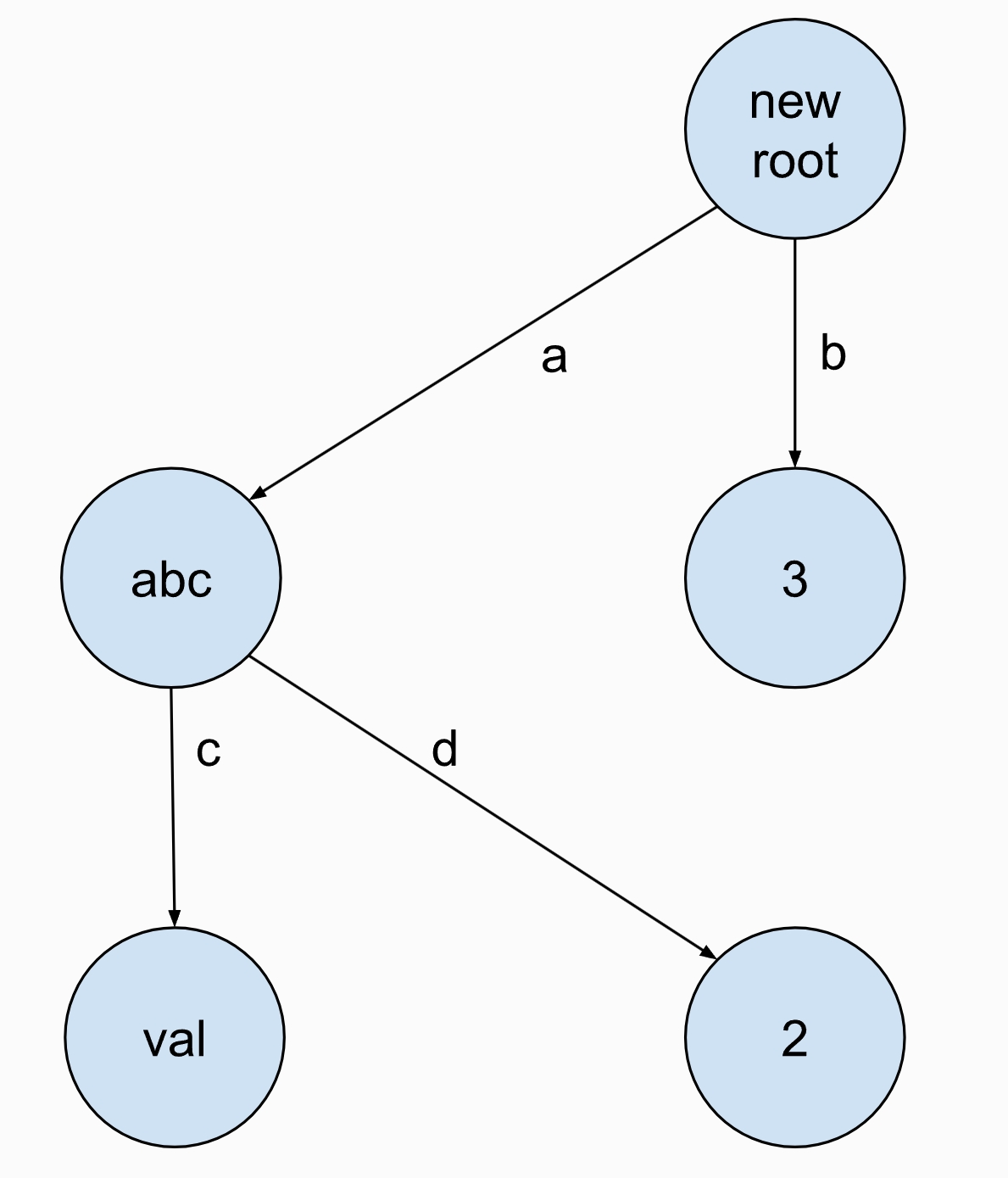
举例如下:
死锁产生的必要条件是
1.互斥 2.请求与保持 3.不可抢占 4.循环等待
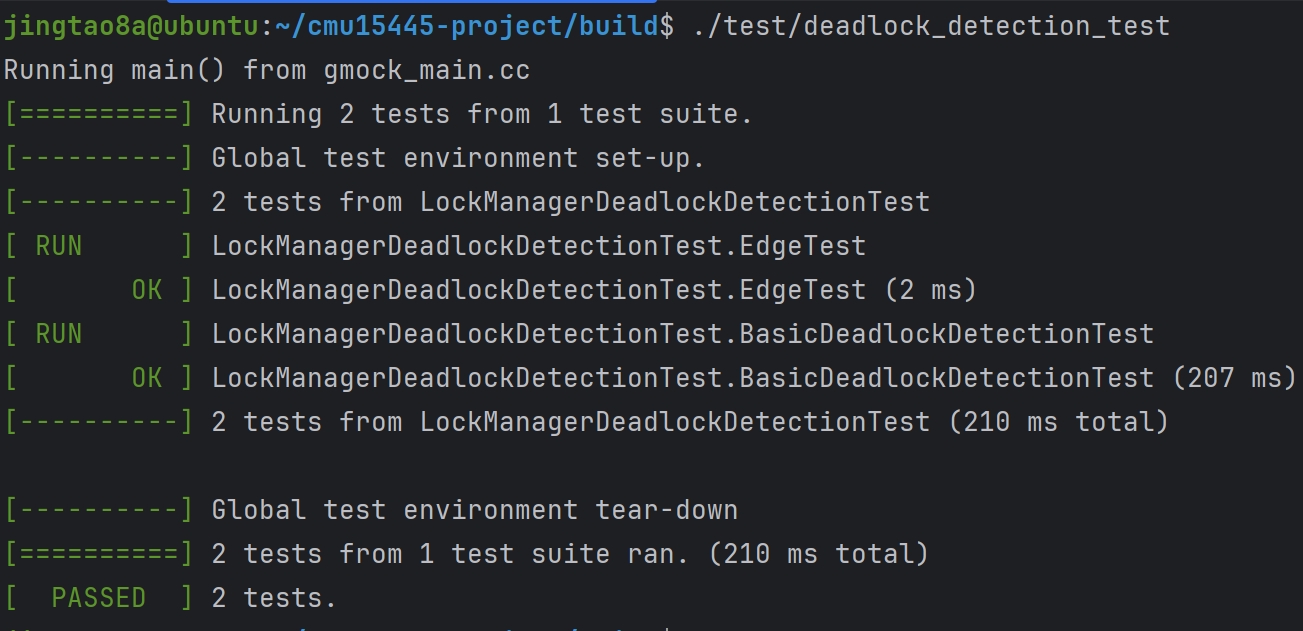
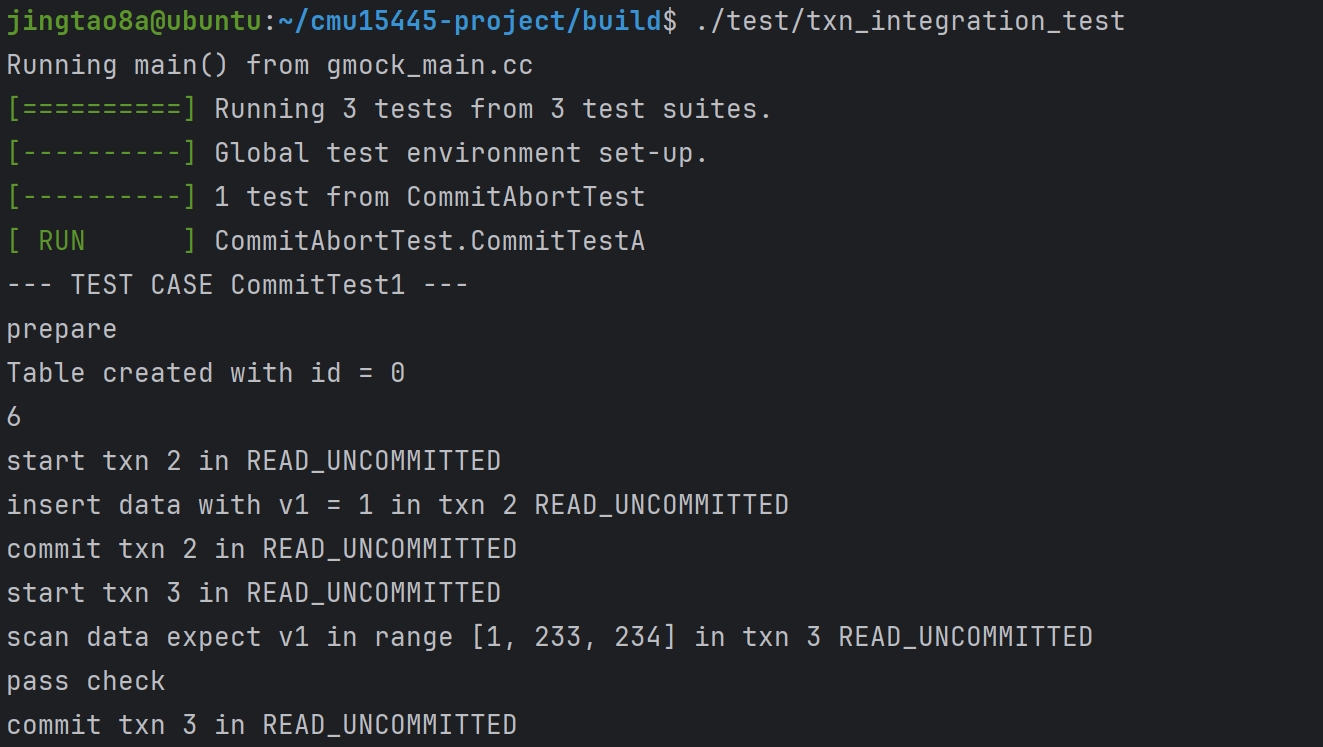
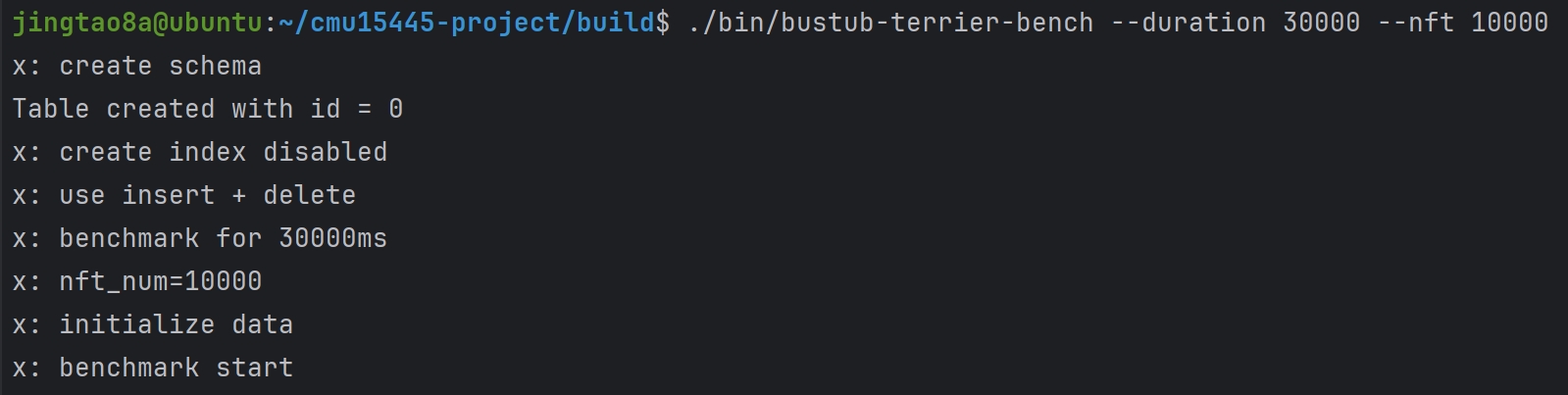
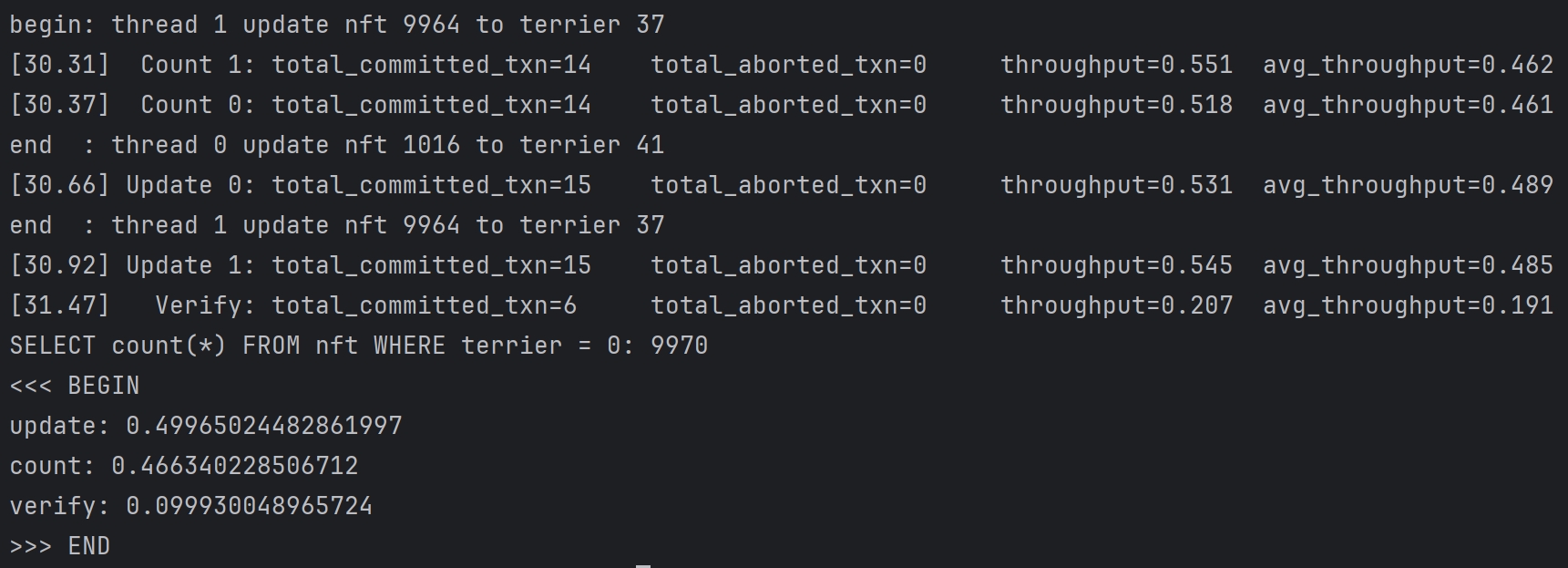
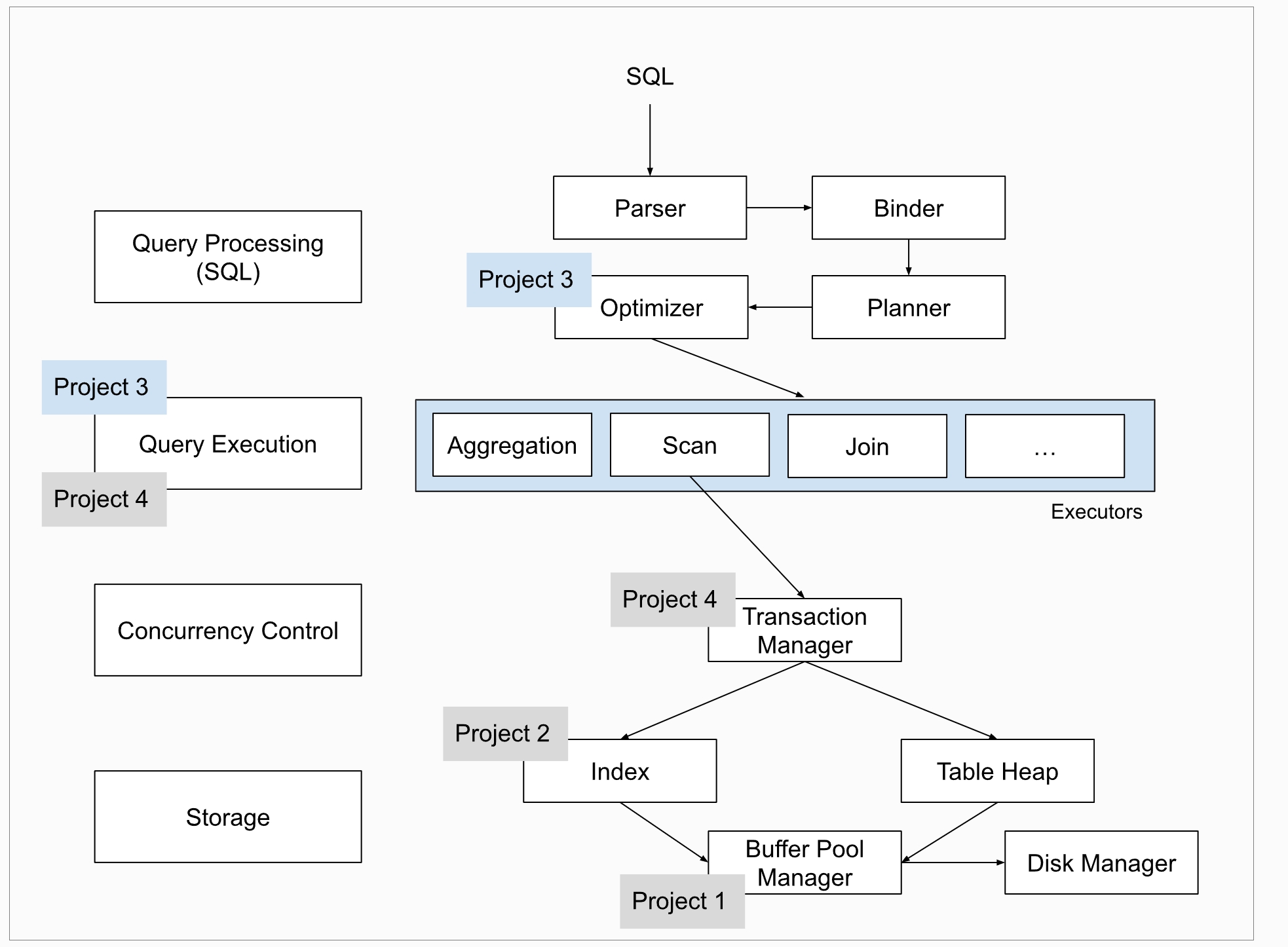
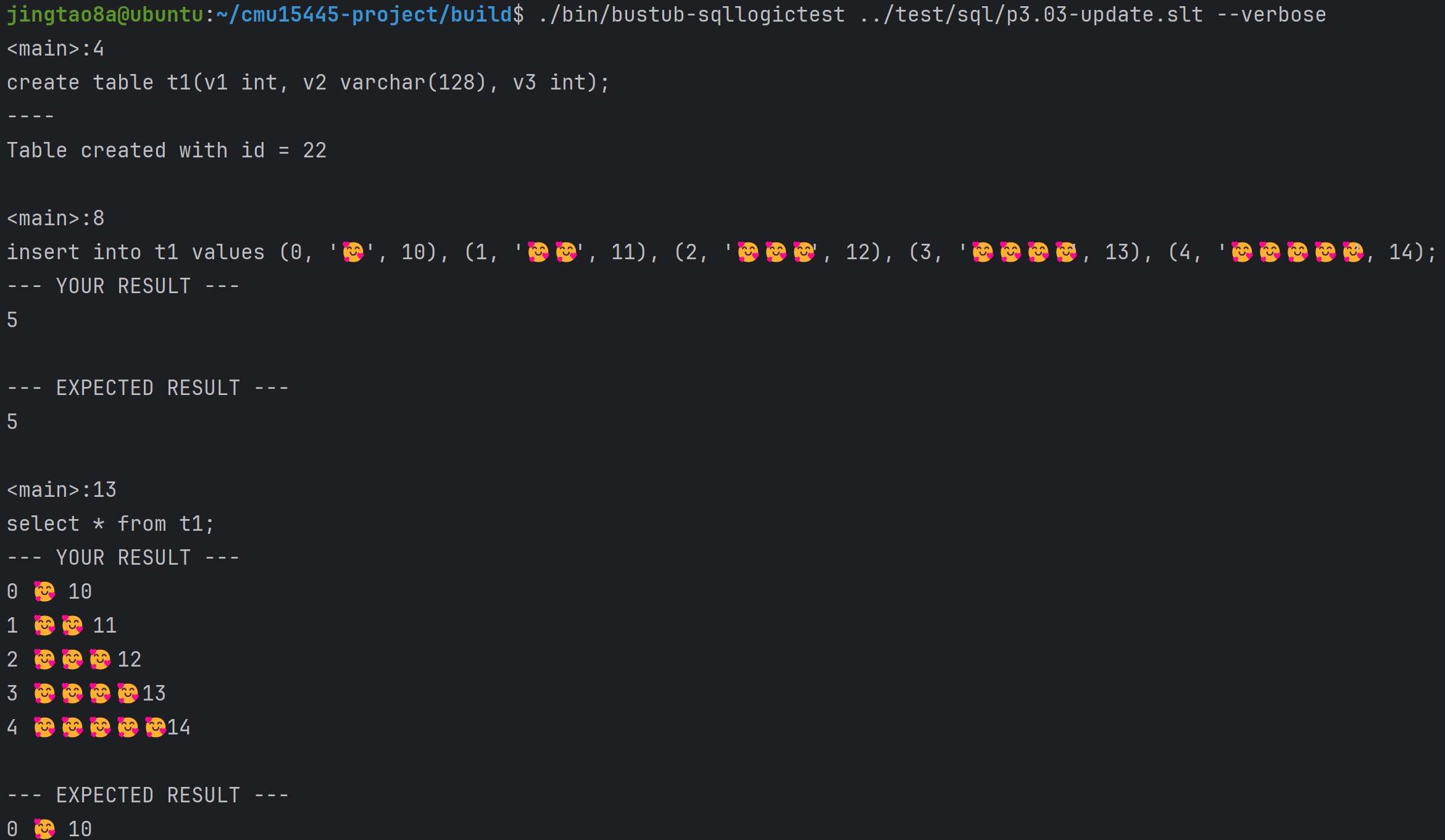
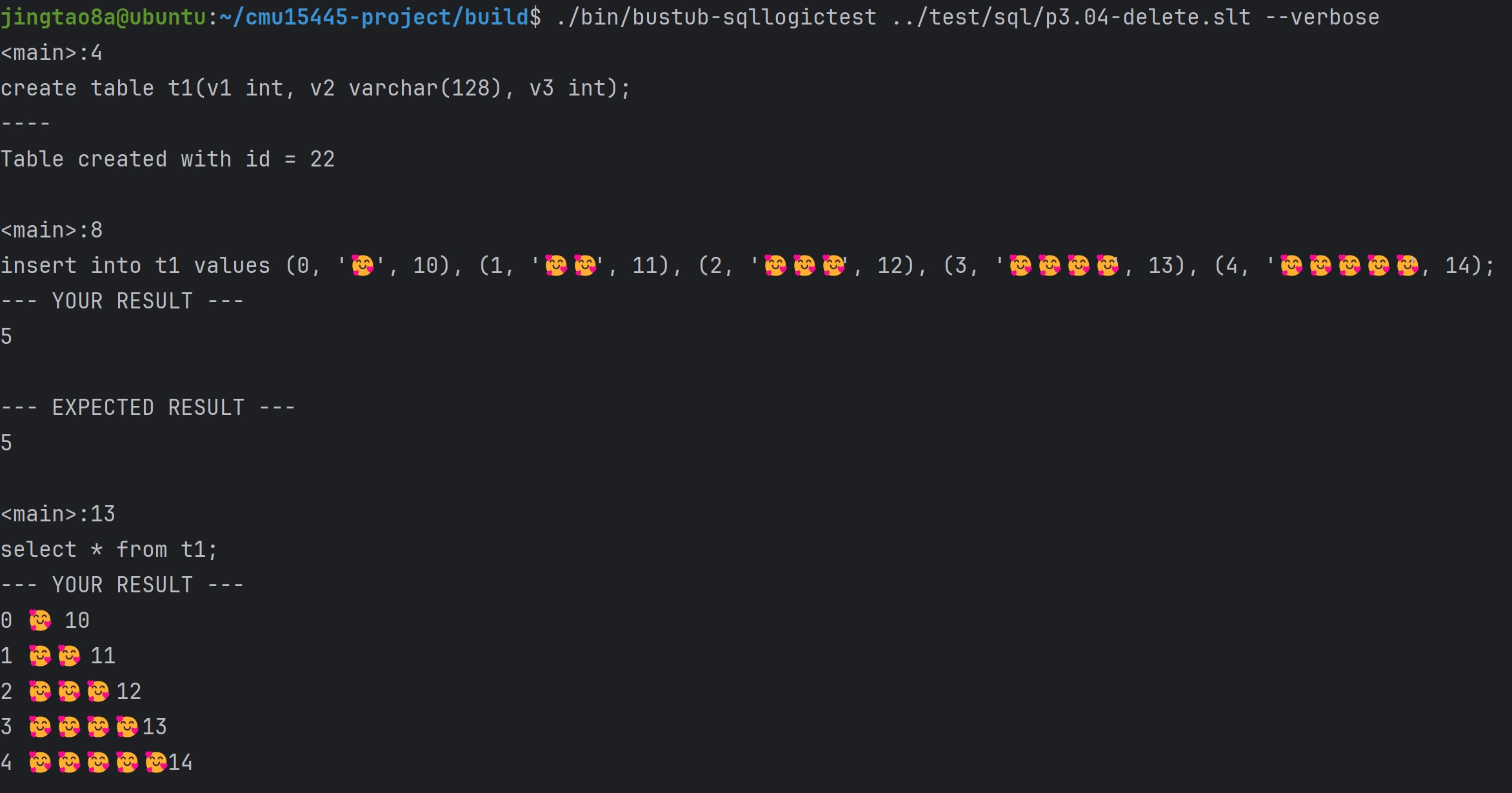
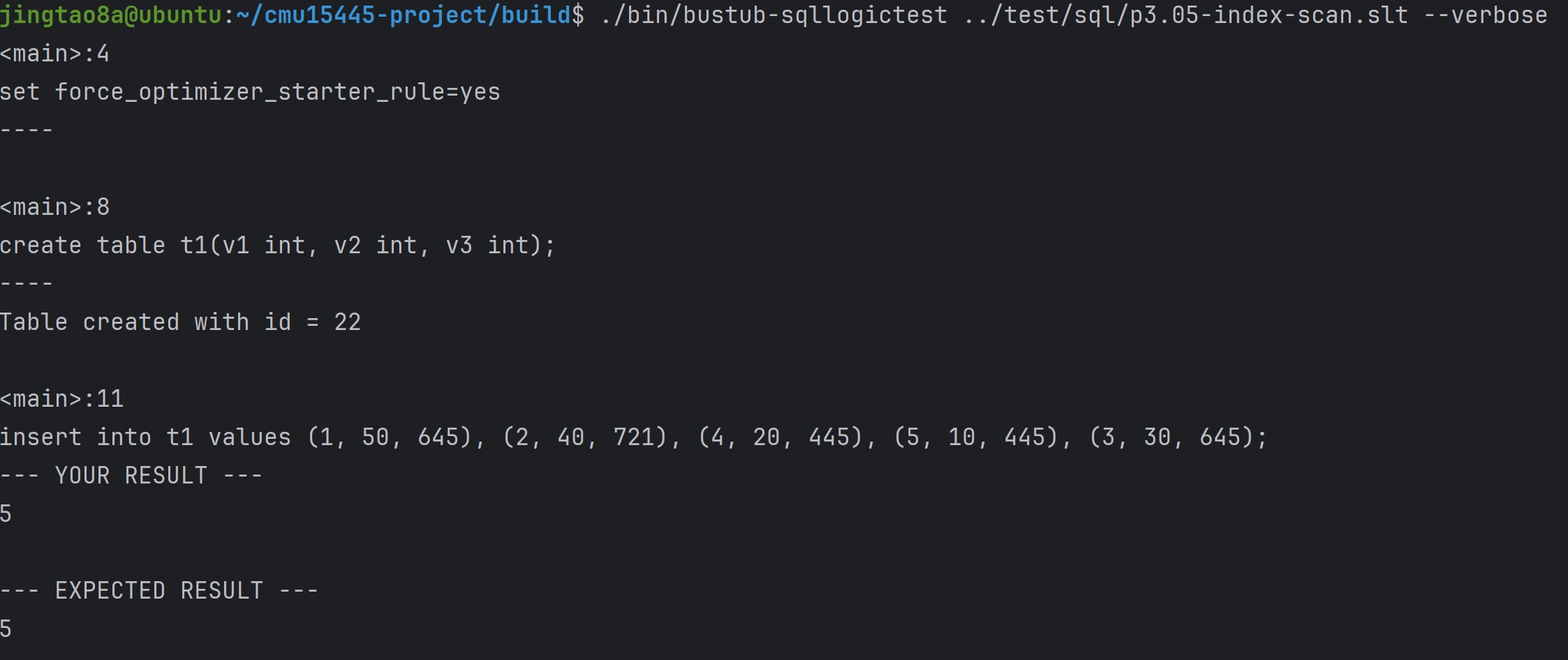
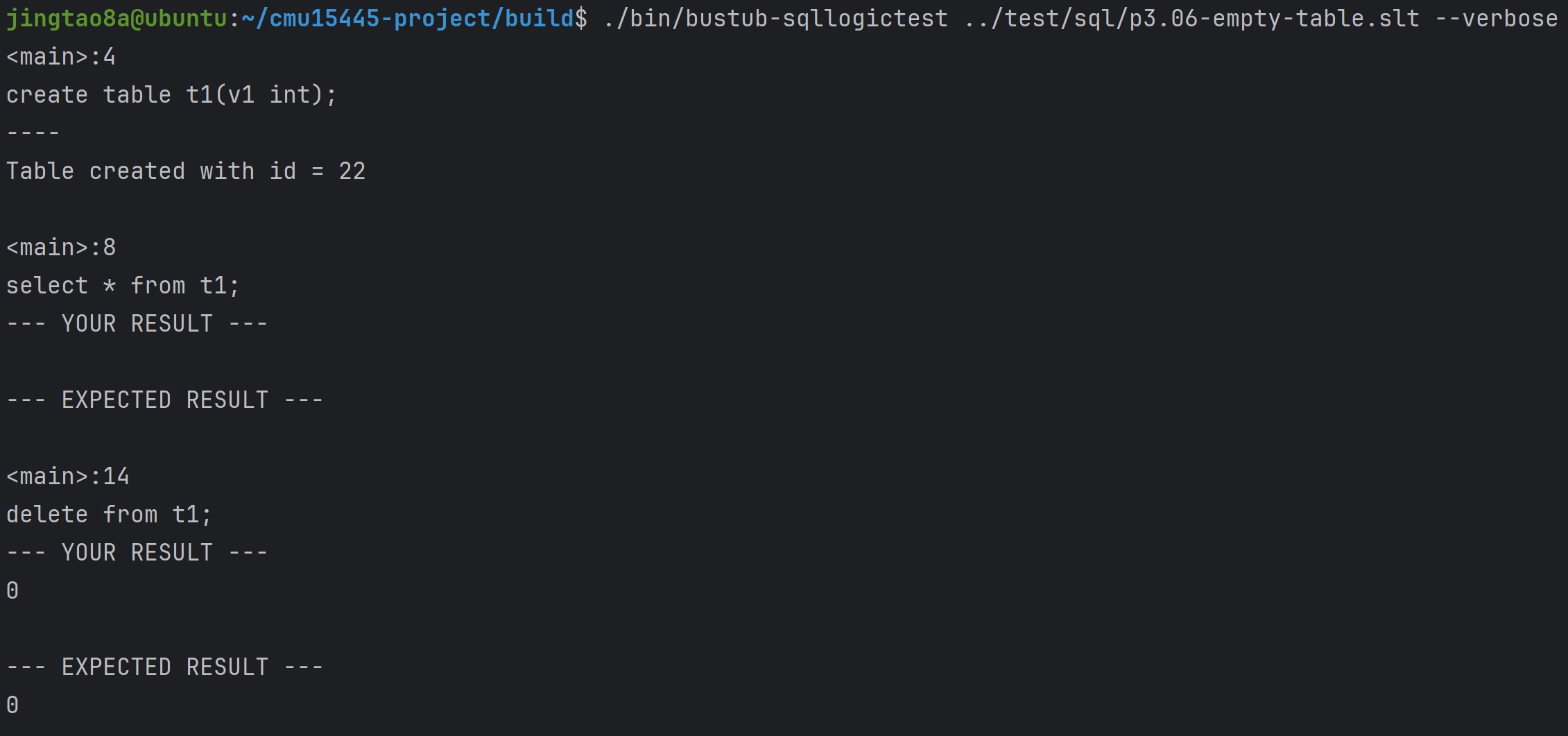
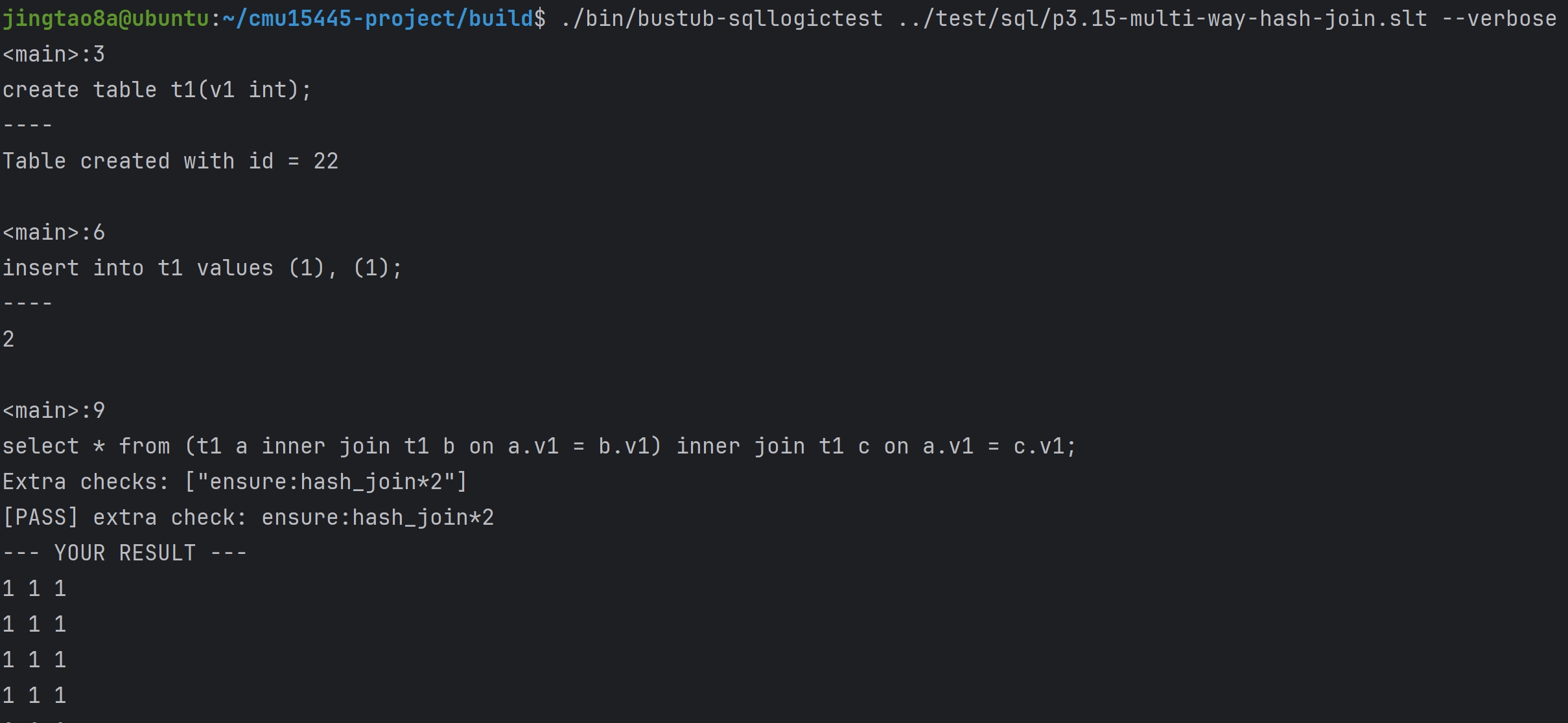
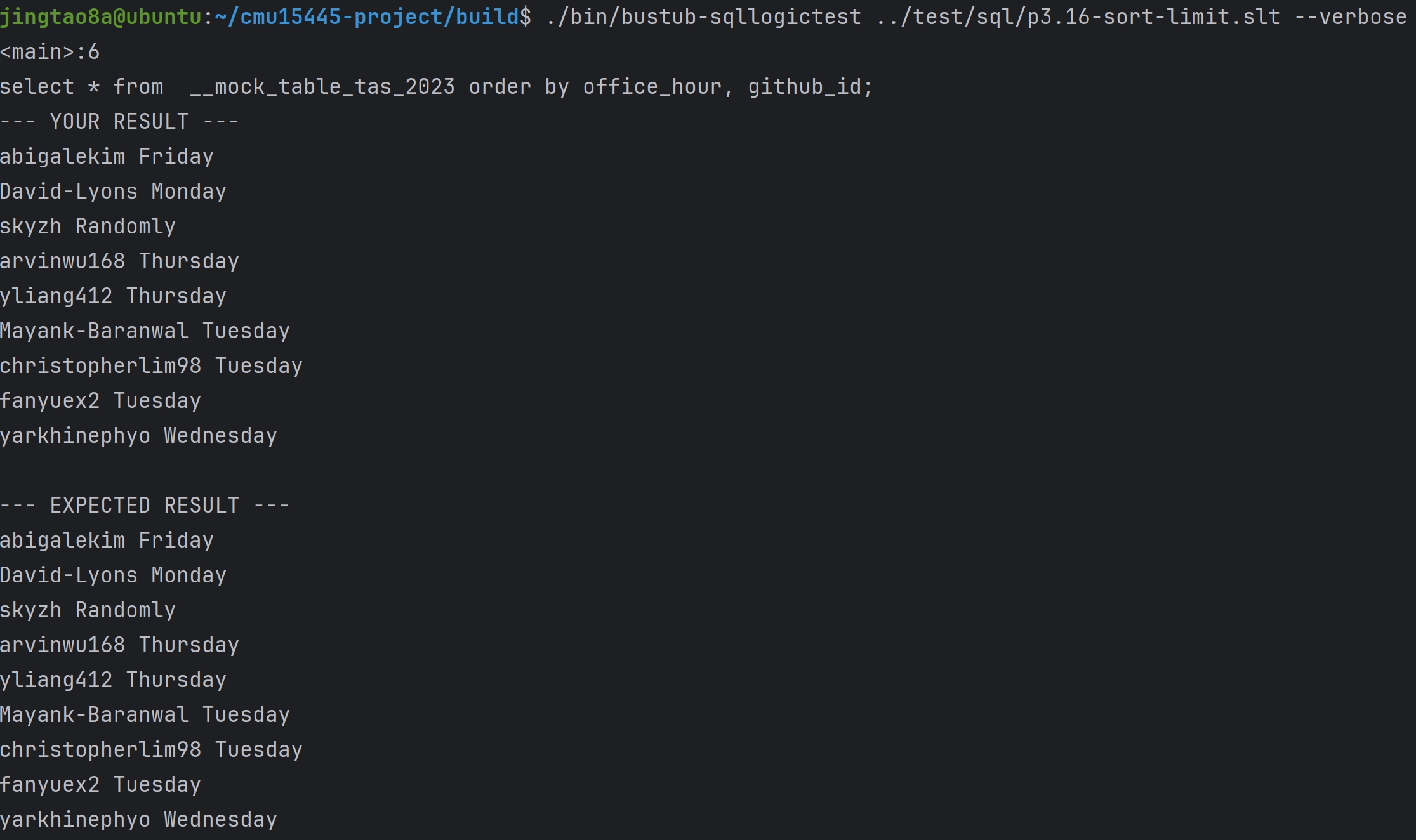
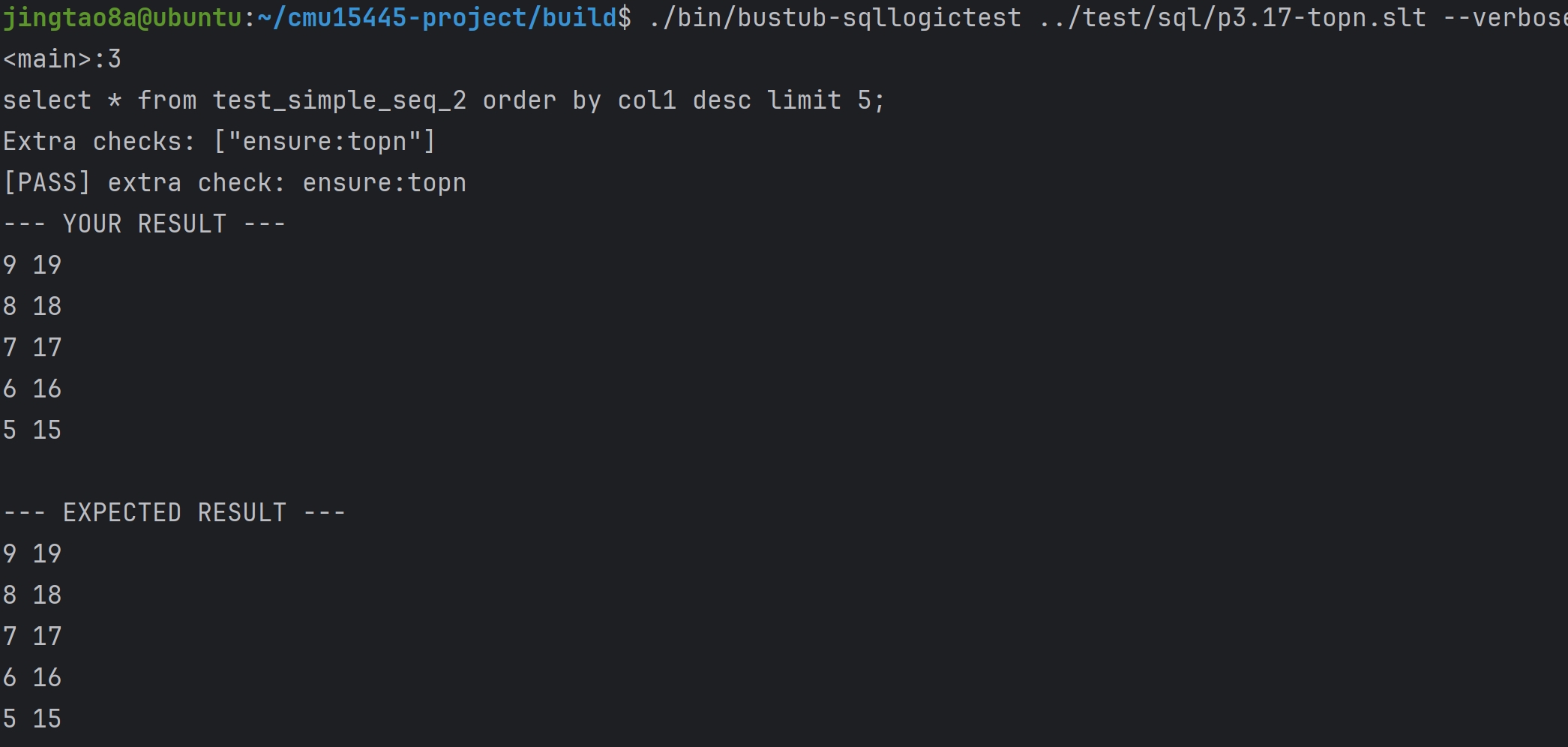
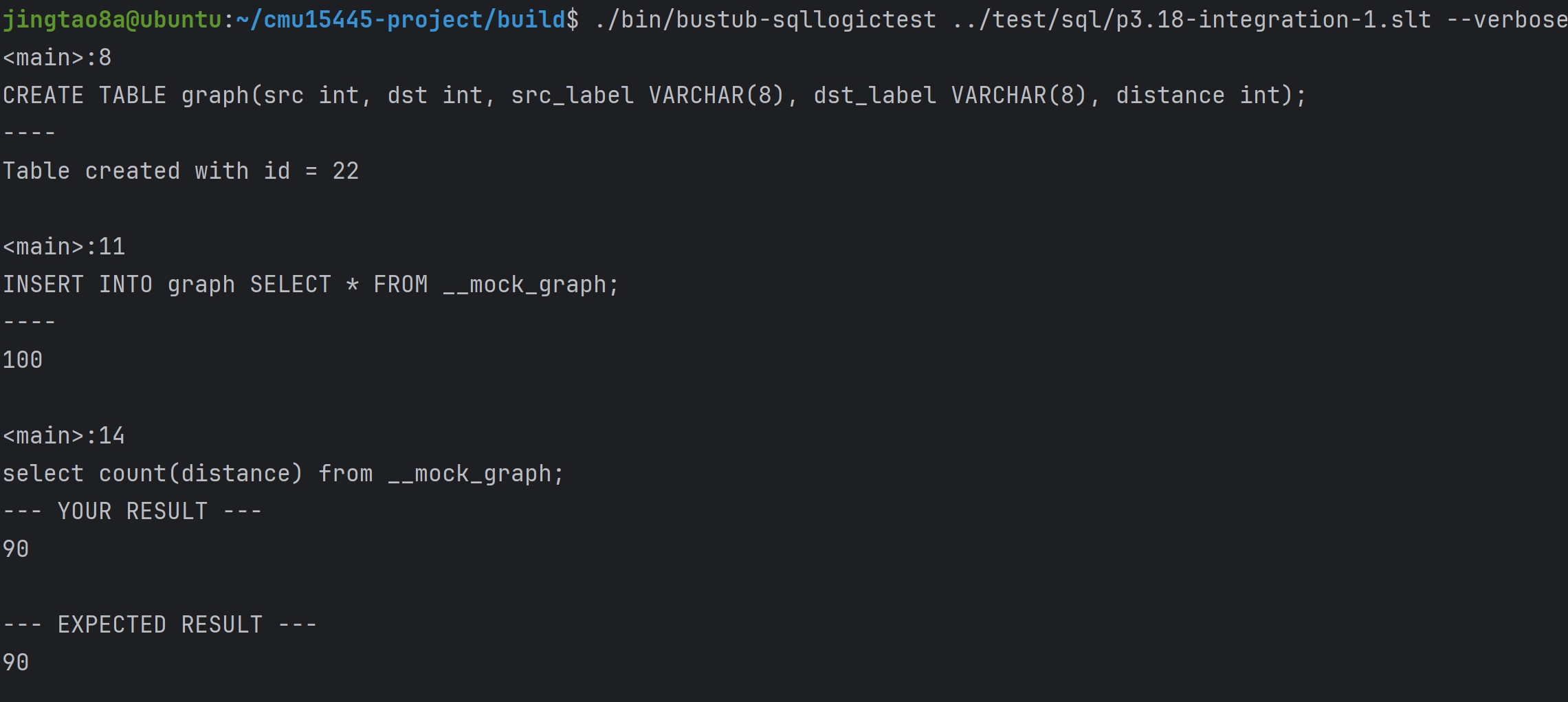
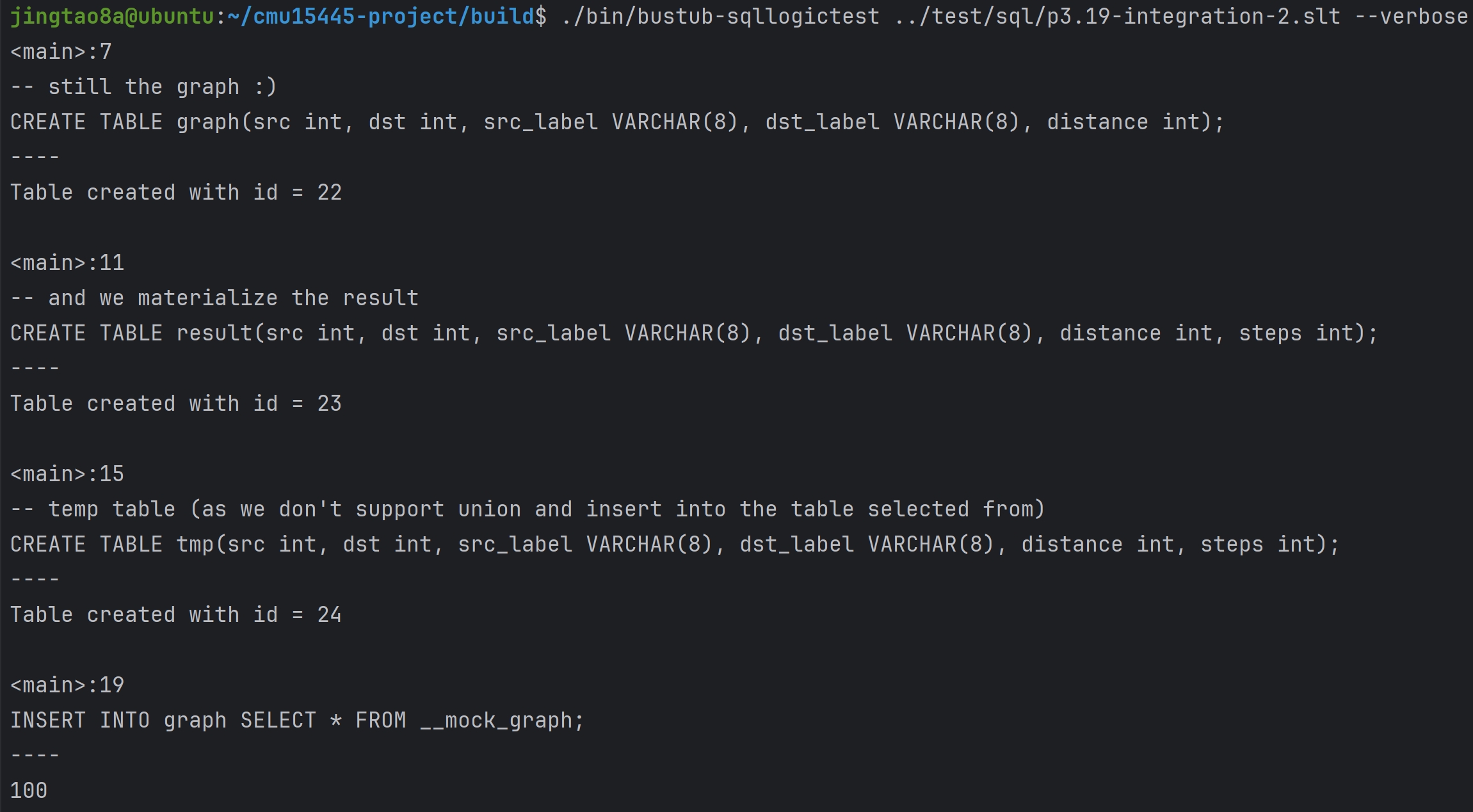
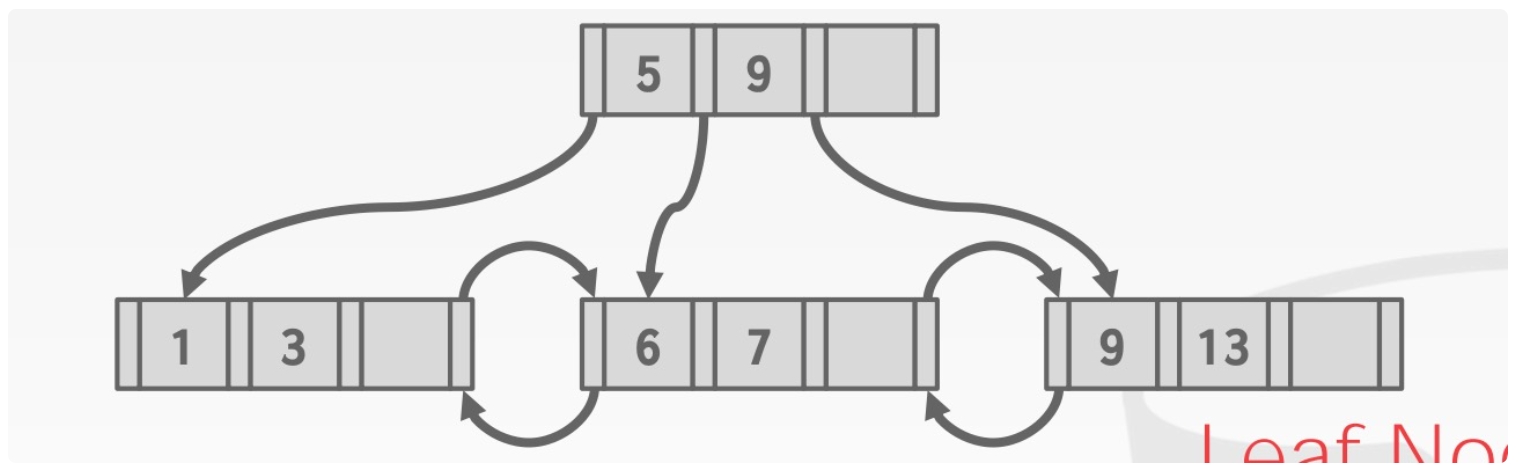
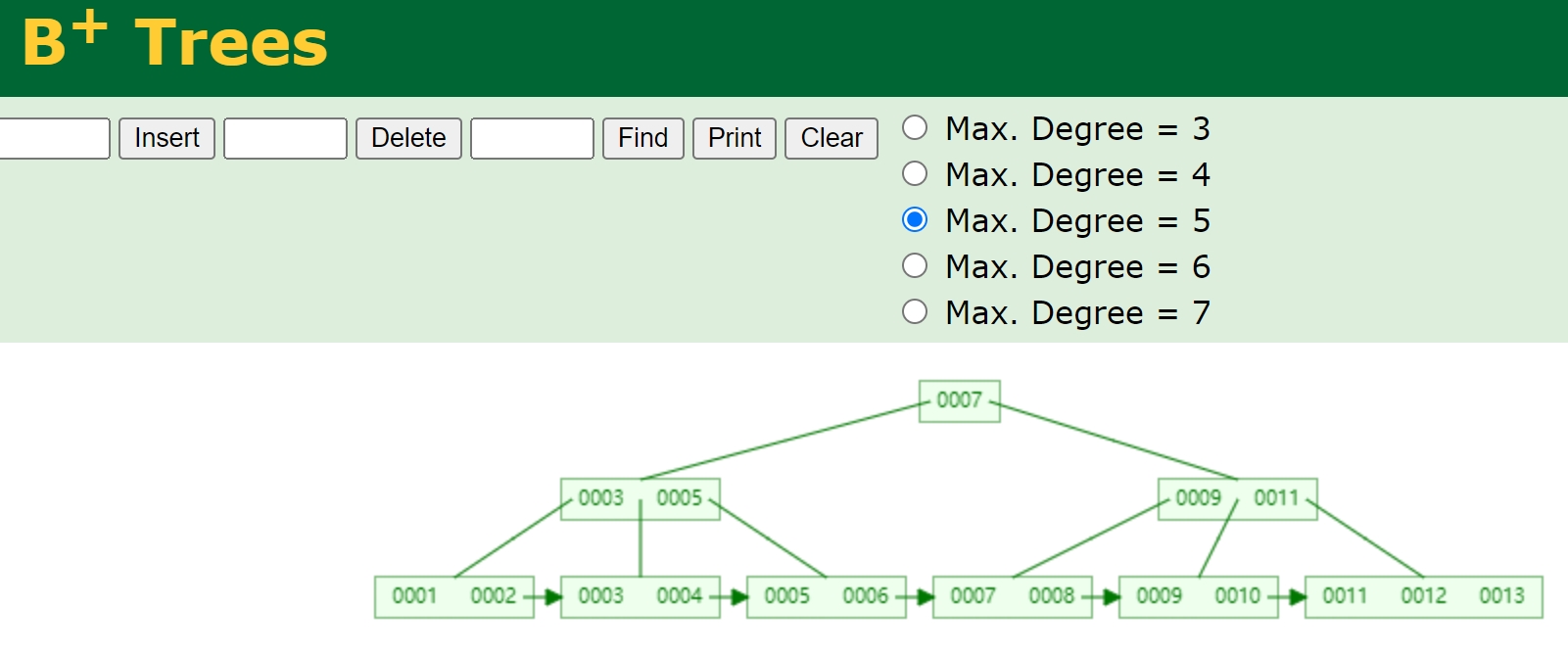
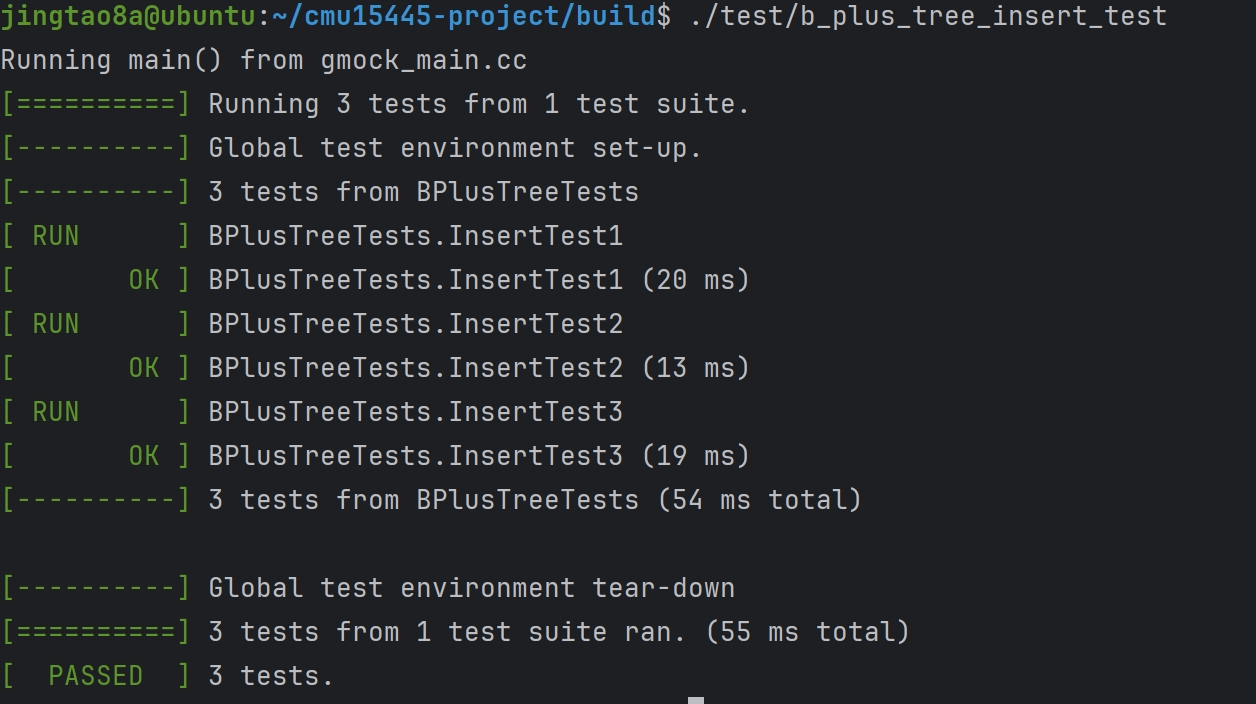
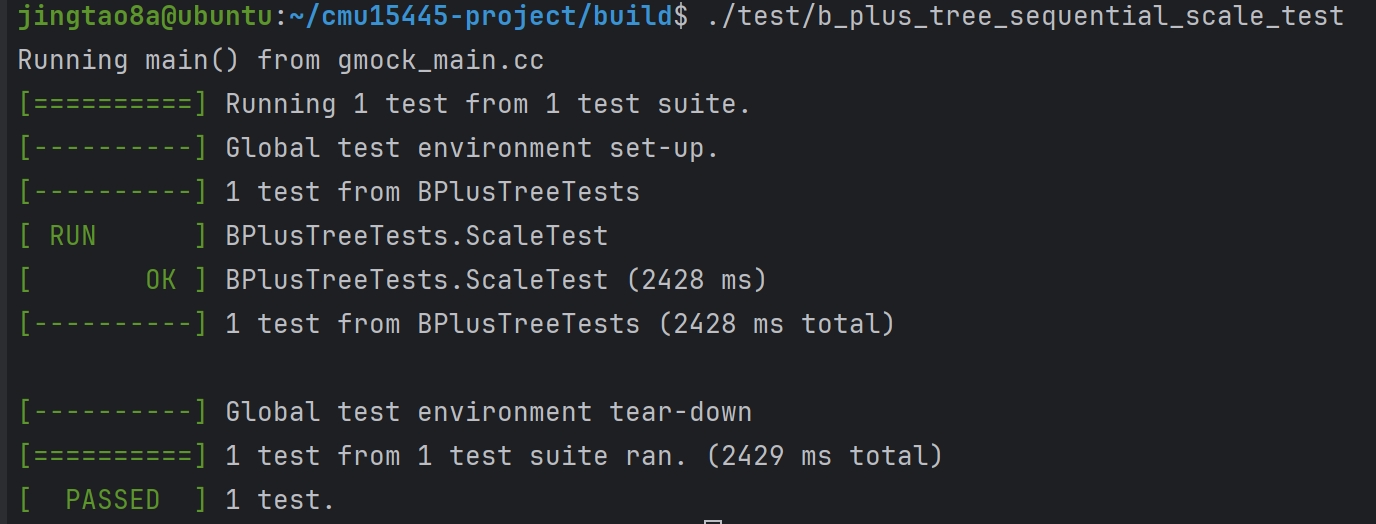
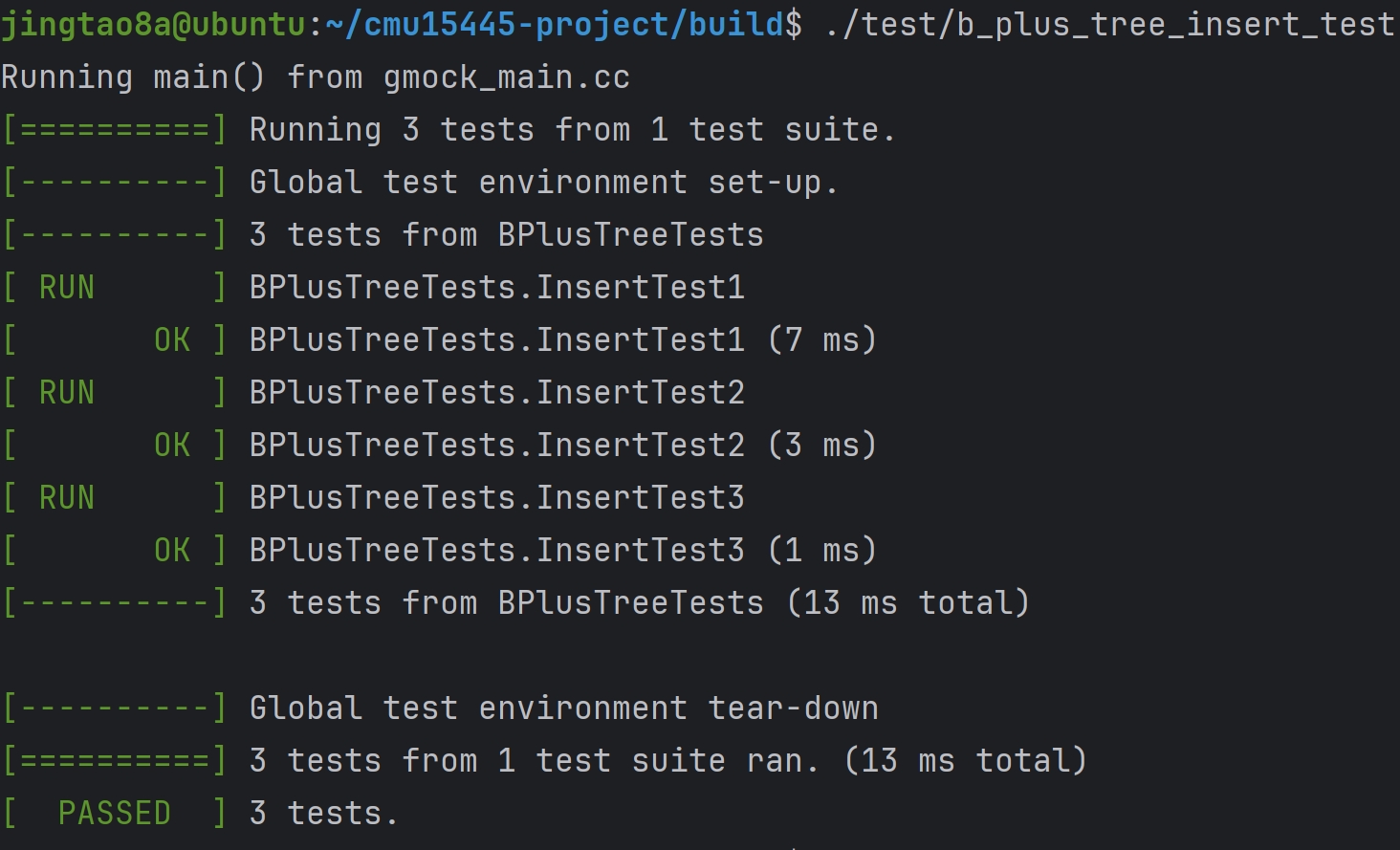
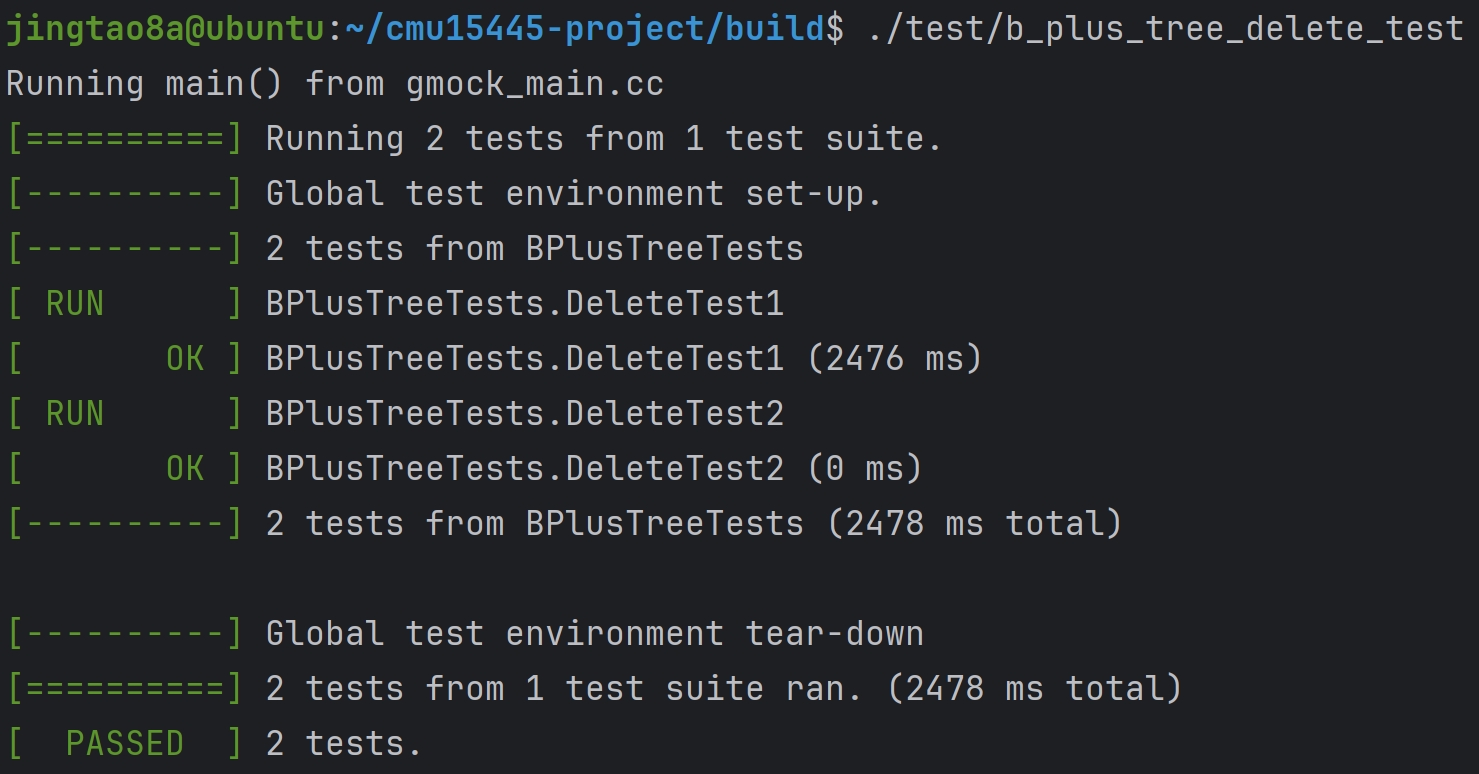
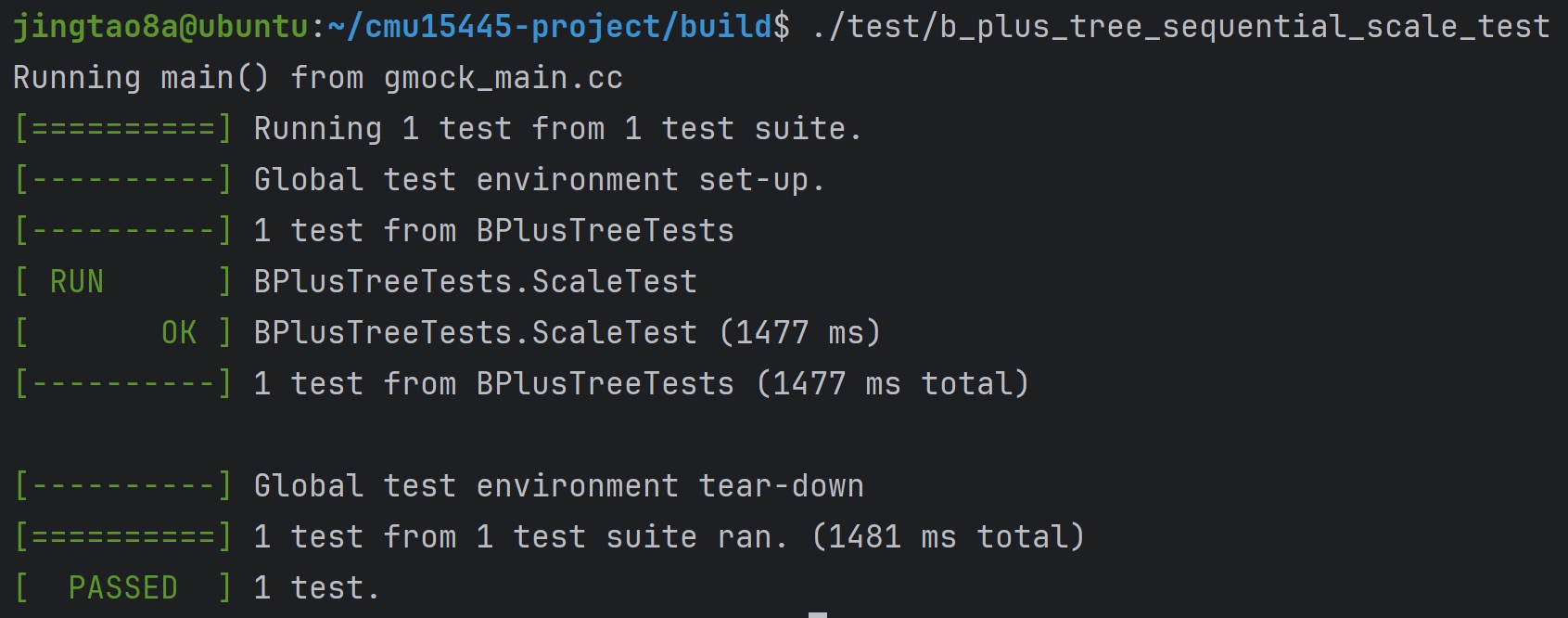
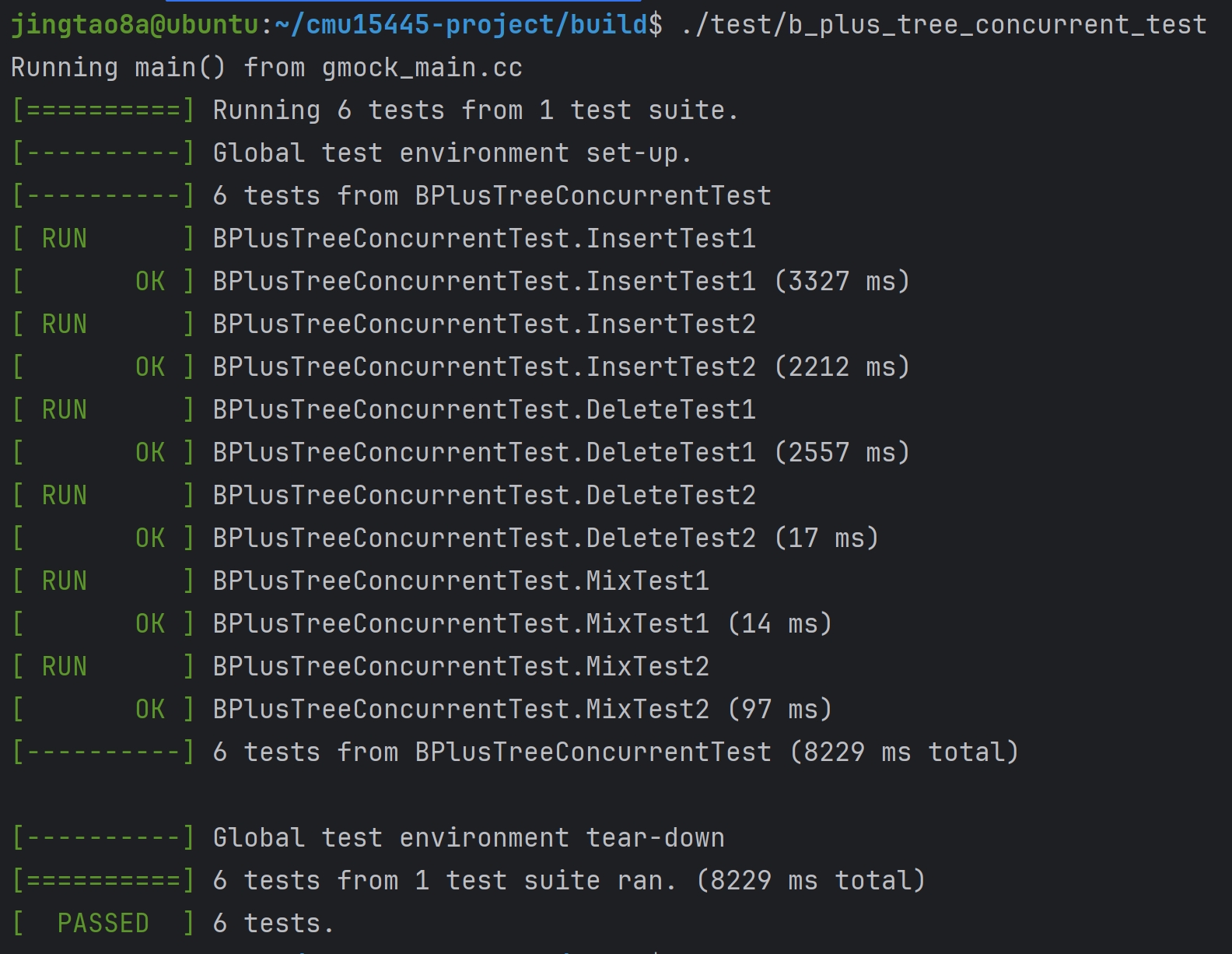
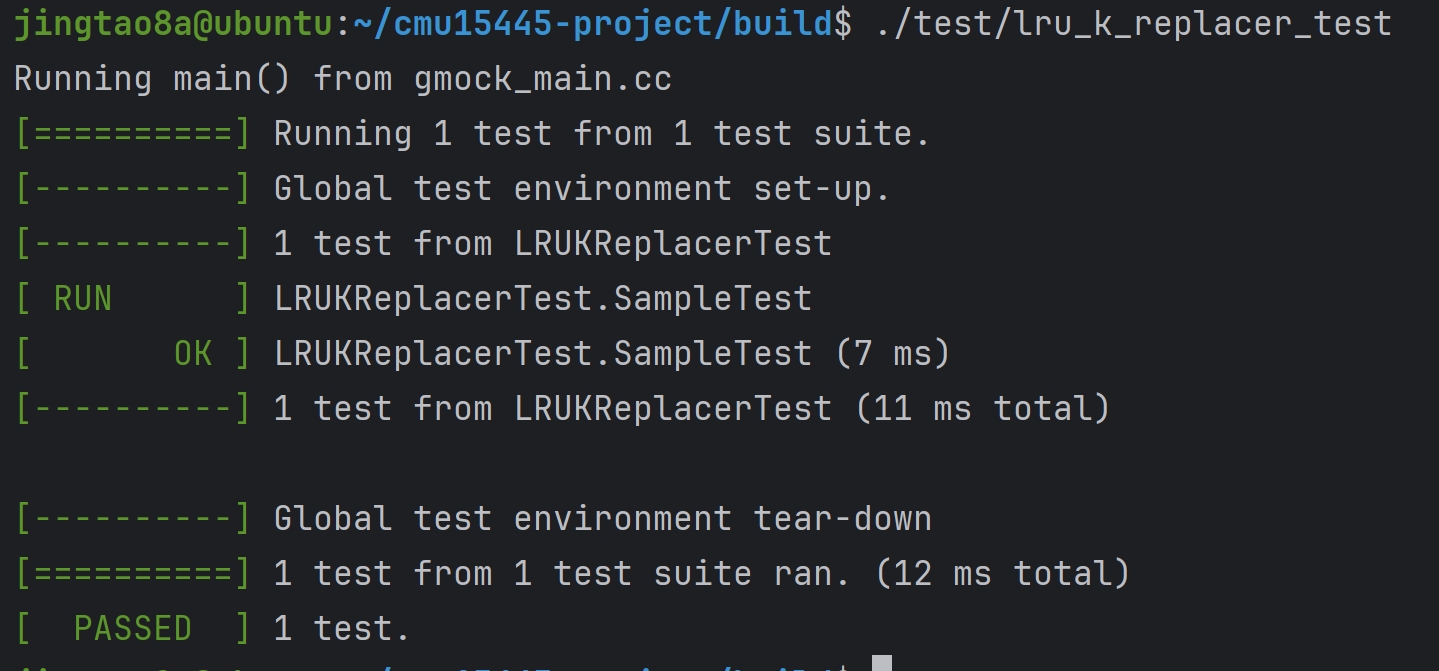
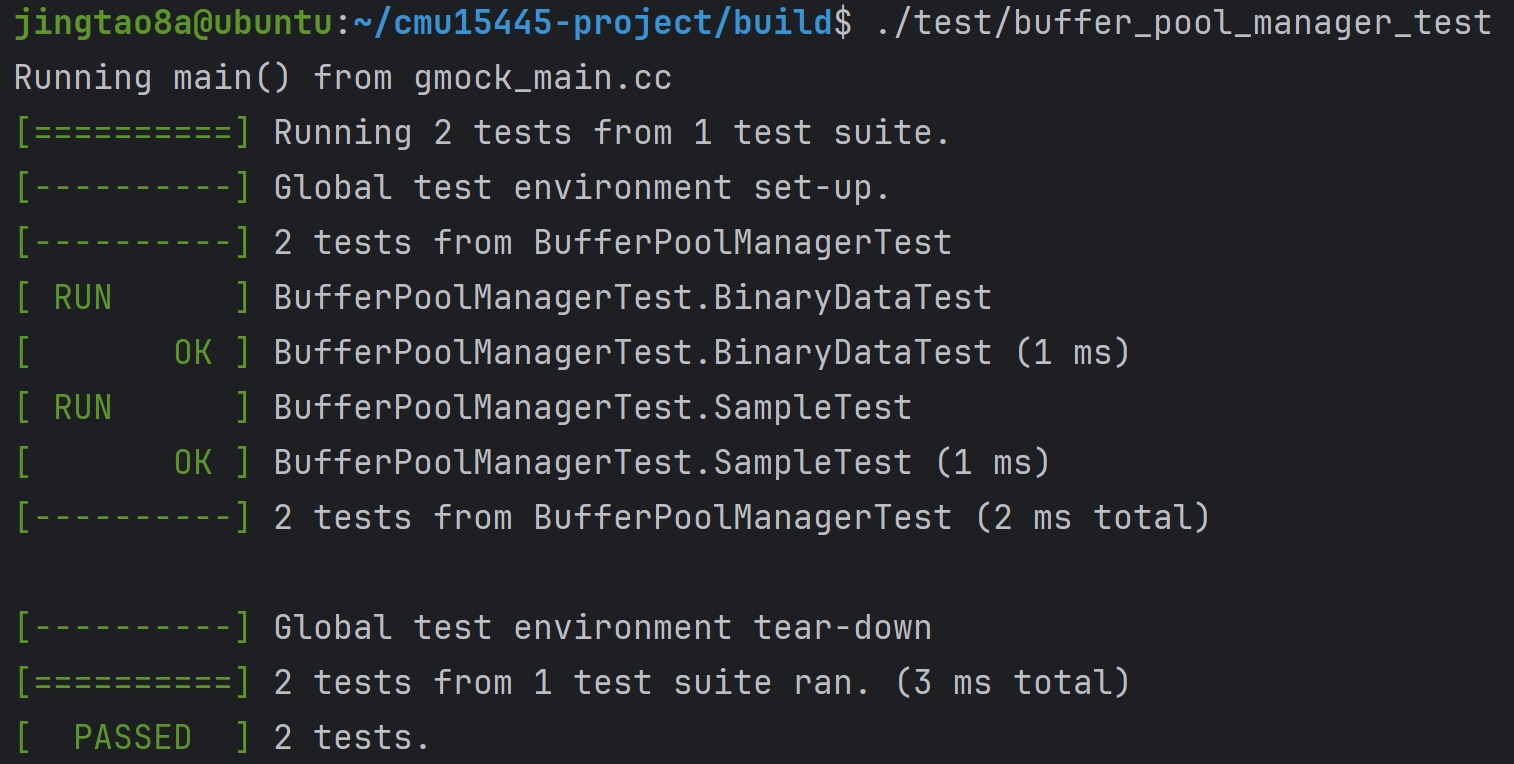
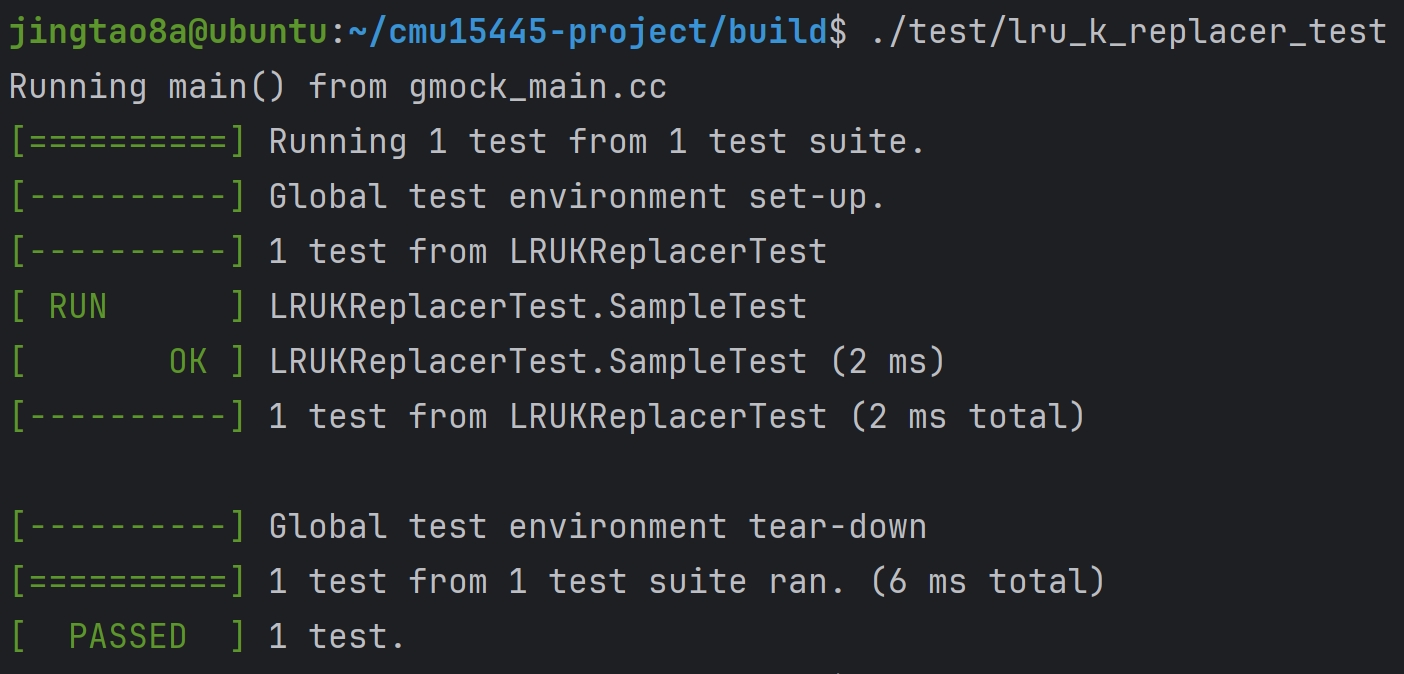
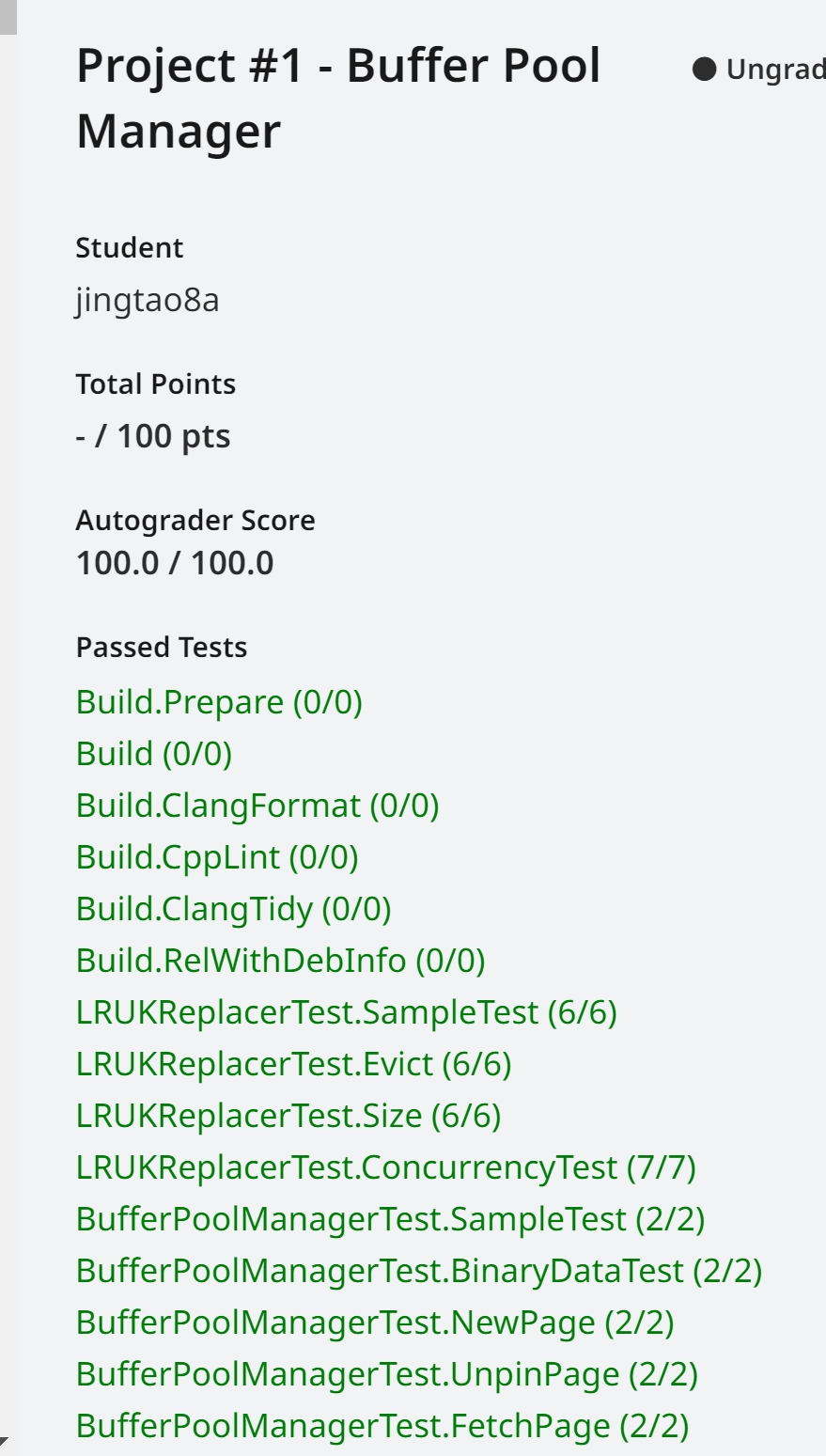
Task#1 Lock Manager
五种锁 S X IS IX SIX 这里只实现三种隔离级别READ_UNCOMMITTED、READ_COMMITTED、REPEATABLE_READ
LOCK NOTE
GENERAL BEHAVIOUR:
Both LockTable() and LockRow() are blocking methods; they should wait till the lock is granted and then return.
If the transaction was aborted in the meantime, do not grant the lock and return false.
MULTIPLE TRANSACTIONS:
LockManager should maintain a queue for each resource; locks should be granted to transactions in a FIFO manner.
If there are multiple compatible lock requests, all should be granted at the same time
as long as FIFO is honoured.
SUPPORTED LOCK MODES:
Table locking should support all lock modes.
Row locking should not support Intention locks. Attempting this should set the TransactionState as
ABORTED and throw a TransactionAbortException (ATTEMPTED_INTENTION_LOCK_ON_ROW)
ISOLATION LEVEL:
REPEATABLE_READ:
The transaction is required to take all locks. All locks are allowed in the GROWING state No locks are allowed in the SHRINKING state
READ_COMMITTED:
The transaction is required to take all locks. All locks are allowed in the GROWING state Only IS, S locks are allowed in the SHRINKING state
READ_UNCOMMITTED:
The transaction is required to take only IX, X locks. X, IX locks are allowed in the GROWING state. S, IS, SIX locks are never allowed
MULTILEVEL LOCKING:
While locking rows, Lock() should ensure that the transaction has an appropriate lock on the table which the row
belongs to. For instance, if an exclusive lock is attempted on a row, the transaction must hold either X, IX, or SIX on the table. If such a lock does not exist on the table, Lock() should set the TransactionState as ABORTED and throw a TransactionAbortException (TABLE_LOCK_NOT_PRESENT)
LOCK UPGRADE:
Calling Lock() on a resource that is already locked should have the following behaviour:
If requested lock mode is the same as that of the lock presently held, Lock() should return true since it already has the lock.
If requested lock mode is different, Lock() should upgrade the lock held by the transaction.
While upgrading, only the following transitions should be allowed:
IS -> [S, X, IX, SIX]
S -> [X, SIX]
IX -> [X, SIX]
SIX -> [X]
Any other upgrade is considered incompatible, and such an attempt should set the TransactionState as ABORTED and throw a TransactionAbortException (INCOMPATIBLE_UPGRADE)
Furthermore, only one transaction should be allowed to upgrade its lock on a given resource. Multiple concurrent lock upgrades on the same resource should set the TransactionState as ABORTED and throw a TransactionAbortException (UPGRADE_CONFLICT).
UNLOCK NOTE
GENERAL BEHAVIOUR:
Both UnlockTable() and UnlockRow() should release the lock on the resource and return. Both should ensure that the transaction currently holds a lock on the resource it is attempting to unlock.
If not, LockManager should set the TransactionState as ABORTED and throw a TransactionAbortException (ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD)
Additionally, unlocking a table should only be allowed if the transaction does not hold locks on any row on that table. If the transaction holds locks on rows of the table, Unlock should set the Transaction State as ABORTED and throw a TransactionAbortException (TABLE_UNLOCKED_BEFORE_UNLOCKING_ROWS).
Finally, unlocking a resource should also grant any new lock requests for the resource (if possible).
TRANSACTION STATE UPDATE
REPEATABLE_READ:
Unlocking S/X locks should set the transaction state to SHRINKING
READ_COMMITTED:
Unlocking X locks should set the transaction state to SHRINKING.
Unlocking S locks does not affect transaction state.
READ_UNCOMMITTED:
Unlocking X locks should set the transaction state to SHRINKING.
S locks are not permitted under READ_UNCOMMITTED.
The behaviour upon unlocking an S lock under this isolation level is undefined.
table_lock_map_latch_.lock(); if (table_lock_map_.count(oid) == 0) { table_lock_map_latch_.unlock(); ABORT_FOR_REASON_DIRECTLY_OR_NOT(AbortReason::ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD, true);//该table未加锁 } auto lrq = table_lock_map_[oid]; std::unique_lock<std::mutex> lock(lrq->latch_); table_lock_map_latch_.unlock();
for (auto iter = lrq->request_queue_.begin(); iter != lrq->request_queue_.end(); ++iter) { auto lr = *iter; if (lr->granted_ && lr->txn_id_ == txn->GetTransactionId()) {//找到该事务对该table的LockRequest auto iso_level = txn->GetIsolationLevel(); switch (iso_level) { case IsolationLevel::REPEATABLE_READ: if (lr->lock_mode_ == LockMode::SHARED || lr->lock_mode_ == LockMode::EXCLUSIVE) { txn->SetState(TransactionState::SHRINKING); // LOG_DEBUG("txn:%d be set SHRINGKING", txn->GetTransactionId()); } break; case IsolationLevel::READ_COMMITTED: case IsolationLevel::READ_UNCOMMITTED: if (lr->lock_mode_ == LockMode::EXCLUSIVE) { txn->SetState(TransactionState::SHRINKING); } break; default: UNREACHABLE("wrong IsolationLevel"); }
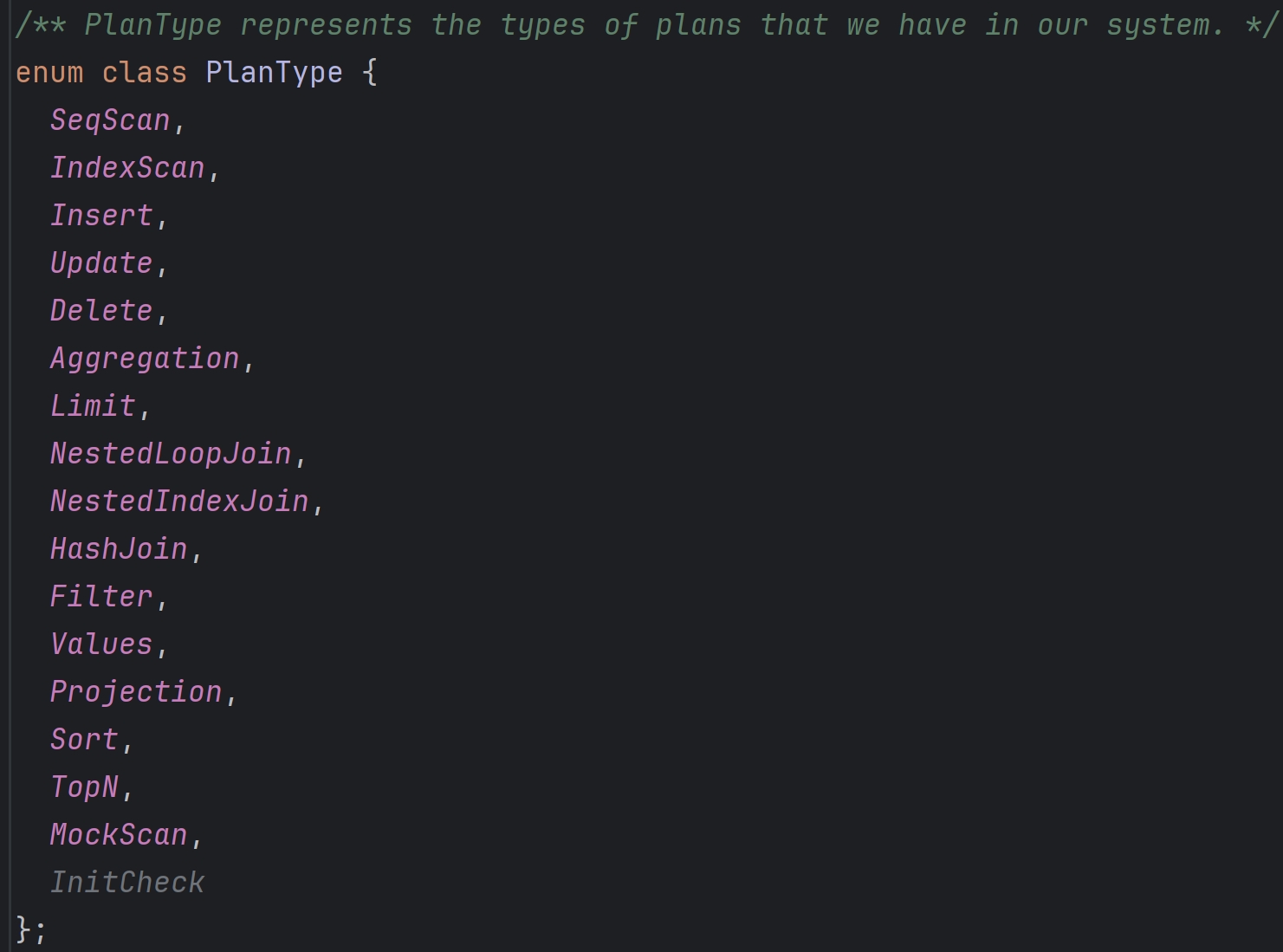
structTableInfo { /** The table schema */ Schema schema_; /** The table name */ const std::string name_; /** An owning pointer to the table heap */ std::unique_ptr<TableHeap> table_; /** The table OID */ consttable_oid_t oid_; };
structIndexInfo { /** The schema for the index key */ Schema key_schema_; /** The name of the index */ std::string name_; /** An owning pointer to the index */ std::unique_ptr<Index> index_; /** The unique OID for the index */ index_oid_t index_oid_; /** The name of the table on which the index is created */ std::string table_name_; /** The size of the index key, in bytes */ constsize_t key_size_; };
//添加数据成员 classUpdateExecutor { const UpdatePlanNode *plan_;//对应的UpdatePlanNode /** Metadata identifying the table that should be updated */ const TableInfo *table_info_;//要update的table /** The child executor to obtain value from */ std::unique_ptr<AbstractExecutor> child_executor_;//孩子executor
classSimpleAggregationHashTable { private: /** The hash table is just a map from aggregate keys to aggregate values */ std::unordered_map<AggregateKey, AggregateValue> ht_{}; /** The aggregate expressions that we have */ const std::vector<AbstractExpressionRef> &agg_exprs_; /** The types of aggregations that we have */ const std::vector<AggregationType> &agg_types_; public: autoGenerateInitialAggregateValue() -> AggregateValue { std::vector<Value> values{}; for (constauto &agg_type : agg_types_) { switch (agg_type) { case AggregationType::CountStarAggregate: // Count start starts at zero. values.emplace_back(ValueFactory::GetIntegerValue(0)); break; case AggregationType::CountAggregate: case AggregationType::SumAggregate: case AggregationType::MinAggregate: case AggregationType::MaxAggregate: // Others starts at null. values.emplace_back(ValueFactory::GetNullValueByType(TypeId::INTEGER)); break; } } return {values}; }
voidCombineAggregateValues(AggregateValue *result, const AggregateValue &input){ for (uint32_t i = 0; i < agg_exprs_.size(); i++) { switch (agg_types_[i]) { case AggregationType::CountStarAggregate://count(*)统计null数量 result->aggregates_[i] = {INTEGER, result->aggregates_[i].GetAs<int32_t>() + 1}; break; case AggregationType::CountAggregate://count()不统计null数量 if (input.aggregates_[i].IsNull()) { break; } if (result->aggregates_[i].IsNull()) { result->aggregates_[i] = {INTEGER, 1}; } else { result->aggregates_[i] = {INTEGER, result->aggregates_[i].GetAs<int32_t>() + 1}; } break; case AggregationType::SumAggregate: if (input.aggregates_[i].IsNull()) { break; } if (result->aggregates_[i].IsNull()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Add((input.aggregates_[i])); } break; case AggregationType::MinAggregate: if (input.aggregates_[i].IsNull()) { break; } if (result->aggregates_[i].IsNull()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Min(input.aggregates_[i]); } break; case AggregationType::MaxAggregate: if (input.aggregates_[i].IsNull()) { break; } if (result->aggregates_[i].IsNull()) { result->aggregates_[i] = input.aggregates_[i]; } else { result->aggregates_[i] = result->aggregates_[i].Max(input.aggregates_[i]); } break; } } }
auto &parent_page_guard = ctx.write_set_[ctx.write_set_.size() - 2]; auto parent_page = parent_page_guard.AsMut<InternalPage>(); auto index = parent_page->ValueIndex(leaf_page_guard.PageId()); BUSTUB_ASSERT(index != -1, "index must not be -1"); // 如果有右brother if (index < parent_page->GetSize() - 1) { page_id_t right_brother_page_id = parent_page->GetArray()[index + 1].second; auto right_brother_page_guard = bpm_->FetchPageWrite(right_brother_page_id); auto right_brother_page = right_brother_page_guard.AsMut<LeafPage>();
classLRUKNode { public: /** History of last seen K timestamps of this page. Least recent timestamp stored in front. */ std::list<size_t> history_;//记录一批时间戳 frame_id_t fid_;// bool is_evictable_{false}; };
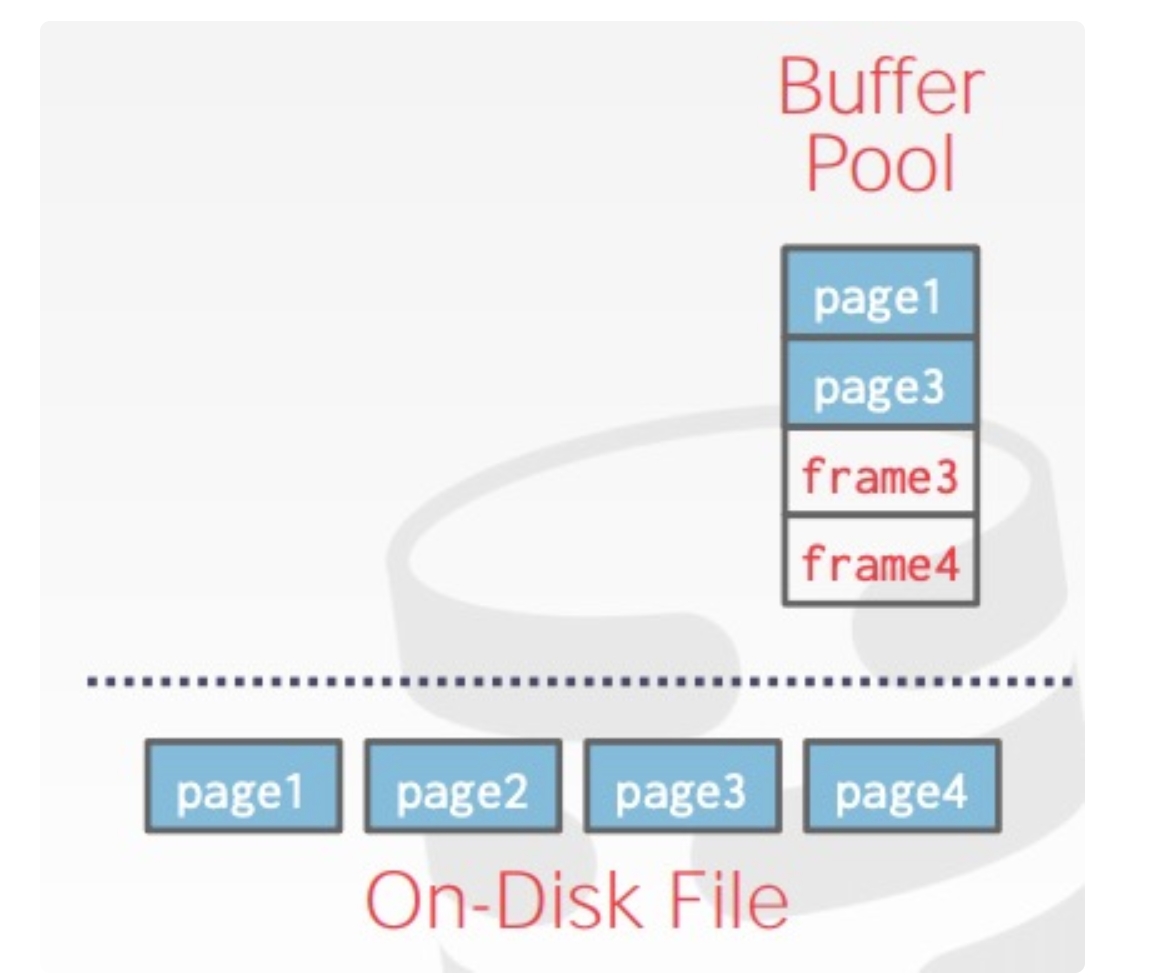
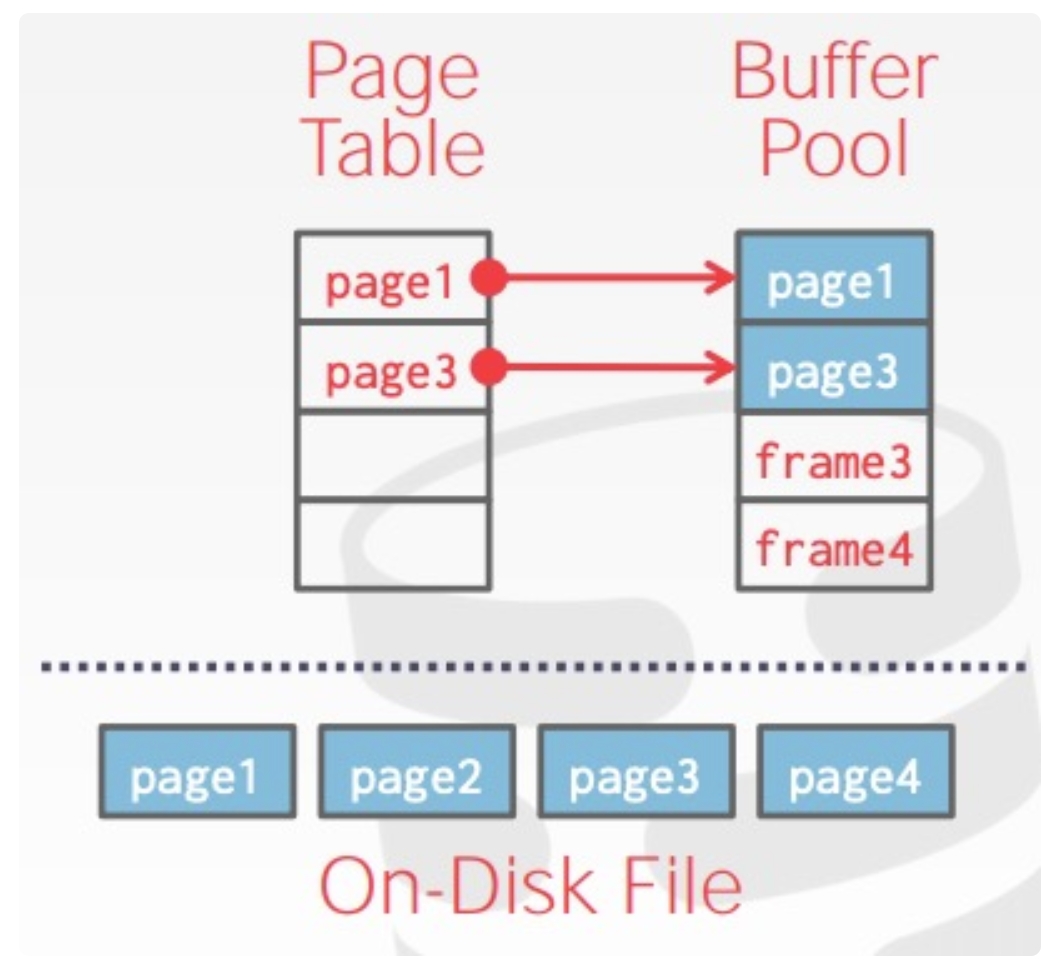
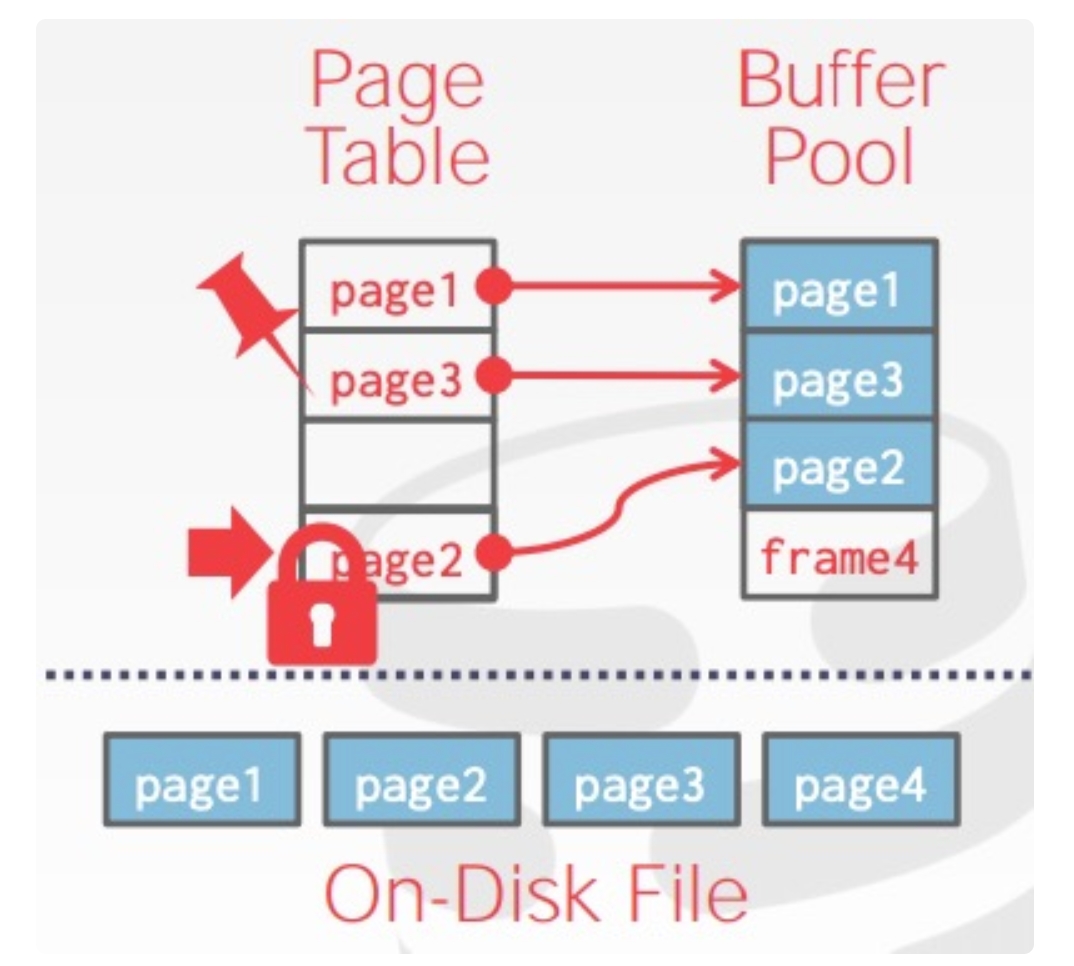
classBufferPoolManager { /** Number of pages in the buffer pool. */ constsize_t pool_size_; /** The next page id to be allocated */ std::atomic<page_id_t> next_page_id_ = 0;
/** Array of buffer pool pages. */ Page *pages_; /** Pointer to the disk manager. */ DiskManager *disk_manager_ __attribute__((__unused__)); /** Pointer to the log manager. Please ignore this for P1. */ LogManager *log_manager_ __attribute__((__unused__)); /** Page table for keeping track of buffer pool pages. */ std::unordered_map<page_id_t, frame_id_t> page_table_; /** Replacer to find unpinned pages for replacement. */ std::unique_ptr<LRUKReplacer> replacer_; /** List of free frames that don't have any pages on them. */ std::list<frame_id_t> free_list_; /** This latch protects shared data structures. We recommend updating this comment to describe what it protects. */ std::mutex latch_; };
// Get the value associated with the given key. // 1. If the key is not in the trie, return nullptr. // 2. If the key is in the trie but the type is mismatched, return nullptr. // 3. Otherwise, return the value. template <classT> autoTrie::Get(std::string_view key)const -> const T * { if (!root_) { returnnullptr; } std::shared_ptr<const TrieNode> ptr(root_); for (char ch : key) { if (ptr->children_.count(ch) == 0) { returnnullptr; } ptr = ptr->children_.at(ch); } if (!ptr->is_value_node_) { returnnullptr; } auto p = std::dynamic_pointer_cast<const TrieNodeWithValue<T>>(ptr); if (!p) { returnnullptr; } return p->value_.get(); }
template <classT> autoTrie::Put(std::string_view key, T value)const -> Trie { // Note that `T` might be a non-copyable type. Always use `std::move` when creating `shared_ptr` on that value.
// You should walk through the trie and create new nodes if necessary. If the node corresponding to the key already // exists, you should create a new `TrieNodeWithValue`. std::shared_ptr<const TrieNode> new_root(nullptr); std::map<char, std::shared_ptr<const TrieNode>> children; if (key.length() == 0) {//key长度为0,表示在root节点put value if (root_) { children = root_->children_; } new_root = std::make_shared<const TrieNodeWithValue<T>>(children, std::make_shared<T>(std::move(value)));//创建一个新的root节点 returnTrie(new_root); }
template <classT> autoTrieStore::Get(std::string_view key) -> std::optional<ValueGuard<T>> { // Pseudo-code: // (1) Take the root lock, get the root, and release the root lock. Don't lookup the value in the // trie while holding the root lock. // (2) Lookup the value in the trie. // (3) If the value is found, return a ValueGuard object that holds a reference to the value and the // root. Otherwise, return std::nullopt. Trie root; { std::lock_guard<std::mutex> guard(root_lock_); root = root_; } const T *val = root.Get<T>(key); if (!val) { return std::nullopt; }
template <classT> voidTrieStore::Put(std::string_view key, T value){ // You will need to ensure there is only one writer at a time. Think of how you can achieve this. // The logic should be somehow similar to `TrieStore::Get`. std::lock_guard<std::mutex> guard(write_lock_); Trie root; { std::lock_guard<std::mutex> guard1(root_lock_); root = root_; }
voidTrieStore::Remove(std::string_view key){ // You will need to ensure there is only one writer at a time. Think of how you can achieve this. // The logic should be somehow similar to `TrieStore::Get`. std::lock_guard<std::mutex> guard(write_lock_); Trie root; { std::lock_guard<std::mutex> guard1(root_lock_); root = root_; }